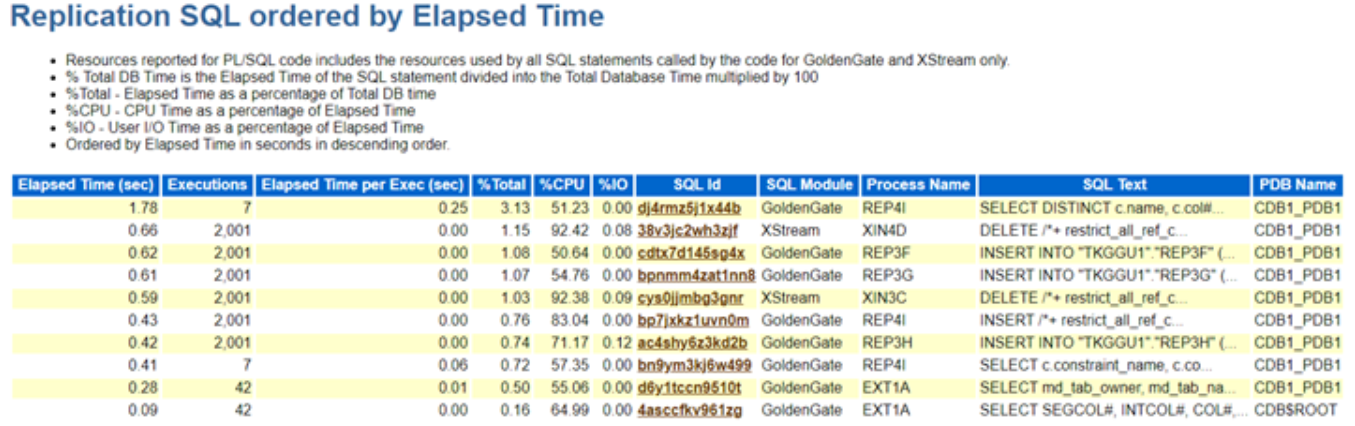
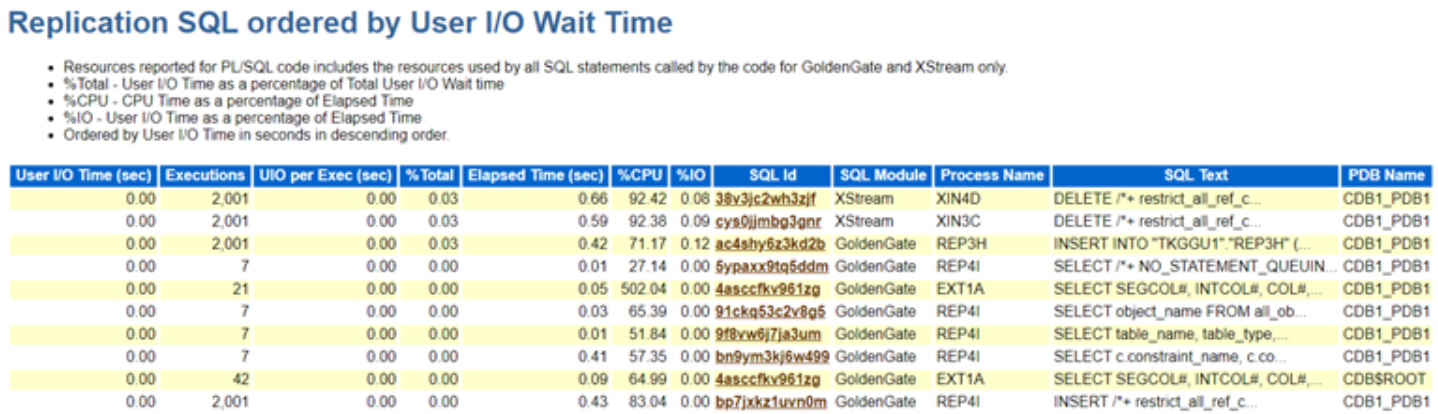
A few weeks ago, we ran into a pretty nasty performance issue on one of our MySQL production-like grade databases. It started with slow application response times and ended with my phone blowing up with alerts. Something was clearly wrong, and while I suspected some bad queries or config mismatches, I needed a fast way to get visibility into what was really happening under the hood.
This is where MySQLTuner came to the rescue, again 🙂 I’ve used this tool in the past, and honestly, it’s one of those underrated gems for DBAs and sysadmins. It’s a Perl script that inspects your MySQL configuration and runtime status and then gives you a human-readable report with recommendations.
Let me walk you through how I used it to identify and fix the problem ..step by step .. including actual command output, what I changed, and the final outcome.
Step 1: Getting MySQLTuner
First things first, if you don’t already have MySQLTuner installed, just download it:
bashCopyEditwget https://raw.githubusercontent.com/major/MySQLTuner-perl/master/mysqltuner.pl
chmod +x mysqltuner.pl
You don’t need to install anything. Just run it like this:
bashCopyEdit./mysqltuner.pl --user=root --pass='YourStrongPassword'
(Note: Avoid running this in peak traffic hours on prod unless you’re sure about your load and risk.)
Step 2: Sample Output Snapshot
Here’s a portion of what I got when I ran it:
>> MySQLTuner 2.6.20
>> Run with '--help' for additional options and output filtering
[OK] Currently running supported MySQL version 5.7.43
[!!] Switch to 64-bit OS - MySQL cannot use more than 2GB of RAM on 32-bit systems
[OK] Operating on 64-bit Linux
-------- Performance Metrics -------------------------------------------------
[--] Up for: 3d 22h 41m (12M q [35.641 qps], 123K conn, TX: 92G, RX: 8G)
[--] Reads / Writes: 80% / 20%
[--] Binary logging is enabled (GTID MODE: ON)
[--] Total buffers: 3.2G global + 2.8M per thread (200 max threads)
[OK] Maximum reached memory usage: 4.2G (27.12% of installed RAM)
[!!] Slow queries: 15% (1M/12M)
[!!] Highest connection usage: 98% (197/200)
[!!] Aborted connections: 2.8K
[!!] Temporary tables created on disk: 37% (1M on disk / 2.7M total)
-------- MyISAM Metrics ------------------------------------------------------
[!!] Key buffer used: 17.2% (89M used / 512M cache)
[!!] Key buffer size / total MyISAM indexes: 512.0M/800.0M
-------- InnoDB Metrics ------------------------------------------------------
[OK] InnoDB buffer pool / data size: 2.0G/1.5G
[OK] InnoDB buffer pool instances: 1
[--] InnoDB Read buffer efficiency: 99.92% (925M hits / 926M total)
[!!] InnoDB Write log efficiency: 85.10% (232417 hits / 273000 total)
[!!] InnoDB log waits: 28
-------- Recommendations -----------------------------------------------------
General recommendations:
Control warning line(s) size by reducing joins or increasing packet size
Increase max_connections slowly if needed
Reduce or eliminate persistent connections
Enable the slow query log to troubleshoot bad queries
Consider increasing the InnoDB log file size
Query cache is deprecated and should be disabled
Variables to adjust:
max_connections (> 200)
key_buffer_size (> 512M)
innodb_log_file_size (>= 512M)
tmp_table_size (> 64M)
max_heap_table_size (> 64M)
Step 3: What I Observed
Here’s what stood out for me:
1. Too many slow queries — 15% of all queries were slow. That’s a huge red flag. This wasn’t being logged properly either — the slow query log was off.
2. Disk-based temporary tables — 37% of temporary tables were being written to disk. This kills performance during joins and sorts.
3. Connections hitting limit — 197 out of 200 max connections used at peak. Close to saturation ..possibly causing application timeouts.
4. MyISAM key buffer inefficient — Key buffer was too small for the amount of MyISAM index data (yes, we still have a couple legacy MyISAM tables..
5. InnoDB log file too small — Frequent log flushing and waits were indicated, meaning innodb_log_file_size wasn’t enough for our write load.
Step 4: Actions I Took
Here’s what I changed based on the output and a quick double-check of our workload patterns:
– Enabled Slow Query Log
sqlCopyEditSET GLOBAL slow_query_log = 'ON';
SET GLOBAL long_query_time = 1;
And updated /etc/my.cnf:
iniCopyEditslow_query_log = 1
slow_query_log_file = /var/log/mysql-slow.log
long_query_time = 1
– Increased tmp_table_size and max_heap_table_size:
iniCopyEdittmp_table_size = 128M
max_heap_table_size = 128M
(This reduced the % of temp tables going to disk.)
– Raised innodb_log_file_size:
iniCopyEditinnodb_log_file_size = 512M
innodb_log_files_in_group = 2
Caution: You need to shut down MySQL cleanly and delete old redo logs before applying this change.
– Raised key_buffer_size:
iniCopyEditkey_buffer_size = 1G
We still had some legacy MyISAM usage and this definitely helped reduce read latency.
– Upped the max_connections a bit (but also discussed with devs about app-level connection pooling):
iniCopyEditmax_connections = 300
Step 5: Post-Change Observations
After making these changes and restarting MySQL (for some of the changes to take effect), here’s what I observed:
- CPU dropped by ~15% at peak hours.
- Threads_running dropped significantly, meaning less contention.
- Temp table usage on disk dropped to 12%.
- Slow query log started capturing some really bad queries, which were fixed in the app code within a few days.
- No more aborted connections or connection errors from the app layer.
Final Thoughts
MySQLTuner is not a magic bullet, but it’s one of those tools that gives you quick, actionable insights without the need to install big observability stacks or pay for enterprise APM tools. I’d strongly suggest any MySQL admin or engineer dealing with production performance issues keep this tool handy.
It’s also good for periodic health checks, even if you’re not in a crisis. Run it once a month or so, and you’ll catch slow config drifts or usage pattern changes.
Resources
If you’ve had a similar experience or used MySQLTuner in your infra, would love to hear what kind of findings you had. Drop them in the comments or message me directly .. Want to know more 🙂 Happy tuning!
Hope It Helped!
Prashant Dixit
Database Architect @RENAPS
Reach us at : https://renaps.com/