Every DBA hits this situation eventually. A query that ran in 40 milliseconds last month now takes eleven minutes, nobody deployed anything, and the developer swears the table “isn’t even that big.” The instinct is to add an index and hope. That works often enough to be genuinely dangerous, because it teaches you nothing about why it worked, and the next time the same trick will quietly fail.
The alternative is to read what the optimizer is actually telling you. MySQL is not shy about it. It will hand you its plan, its estimates, and since 8.0.18 .. its real measured execution, if you know how to ask.
Everything below was run on MySQL 8.0.46 against a schema I built specifically to misbehave: 200,000 customers and 1,000,000 orders, with a status column that is dangerously skewed.
CREATE TABLE customers (
id INT UNSIGNED NOT NULL AUTO_INCREMENT,
email VARCHAR(120) NOT NULL,
country CHAR(2) NOT NULL,
signup_date DATE NOT NULL,
PRIMARY KEY (id),
UNIQUE KEY uq_email (email),
KEY ix_country (country)
) ENGINE=InnoDB;
CREATE TABLE orders (
id BIGINT UNSIGNED NOT NULL AUTO_INCREMENT,
customer_id INT UNSIGNED NOT NULL,
status VARCHAR(12) NOT NULL,
amount DECIMAL(10,2) NOT NULL,
created_at DATETIME NOT NULL,
PRIMARY KEY (id),
KEY ix_customer (customer_id),
KEY ix_status (status)
) ENGINE=InnoDB;
-- The skew is the whole point:
status rows_actual pct
shipped 980123 98.012
pending 12043 1.204
cancelled 4876 0.488
refunded 2958 0.296
Now comes the main topic of discussion, How the optimizer picks the plan ?
MySQL’s optimizer is cost-based, and the machinery is simpler than people assume. There’s no plan cache learning from history, no adaptive feedback loop. Every compilation is a fresh search over possible strategies, and the cheapest estimated plan wins. Before it costs anything, MySQL rewrites the query. Constants get folded (price > 10 * 5 becomes price > 50). Constants get propagated — if you write WHERE a.id = 42 AND a.id = b.a_id, MySQL infers b.a_id = 42 and pushes that predicate straight into b. Simple views get merged into the outer query. And — this one bites people constantly .. an outer join gets silently converted to an inner join if the WHERE clause rejects NULLs on the inner table. Write LEFT JOIN orders o ... WHERE o.status = 'shipped' and you have written an inner join, whether you meant to or not, because a NULL o.status can never equal 'shipped'.
Then comes range analysis, and this is the part that matters most for the rest of this post. For each usable index, MySQL doesn’t just consult stored statistics. It performs an actual B tree search .. records_in_range() .. physically walking into the index to count how many rows fall inside your predicate’s range. This is real work, touching real pages, at plan time.
Join ordering is a greedy search, not exhaustive. Two conditions govern it: optimizer_search_depth (default 62) and optimizer_prune_level (default 1). For three or four tables MySQL will find something near optimal. For fifteen tables it will find a plan, and that plan may be mediocre. Counterintuitively, if you’re joining that many tables and getting bad plans, lowering optimizer_search_depth to 4 or 8 often produces better plans faster, because you stop the optimizer from burning its budget on a search space it can’t cover anyway.
Costs are computed from tunable constants in mysql.server_cost and mysql.engine_cost …. row_evaluate_cost, io_block_read_cost, and friends. You can change them. You almost definately shouldn’t.
Next lets talk about plan generation and tools we have –> Three tools, three different jobs, and people conflate them constantly.
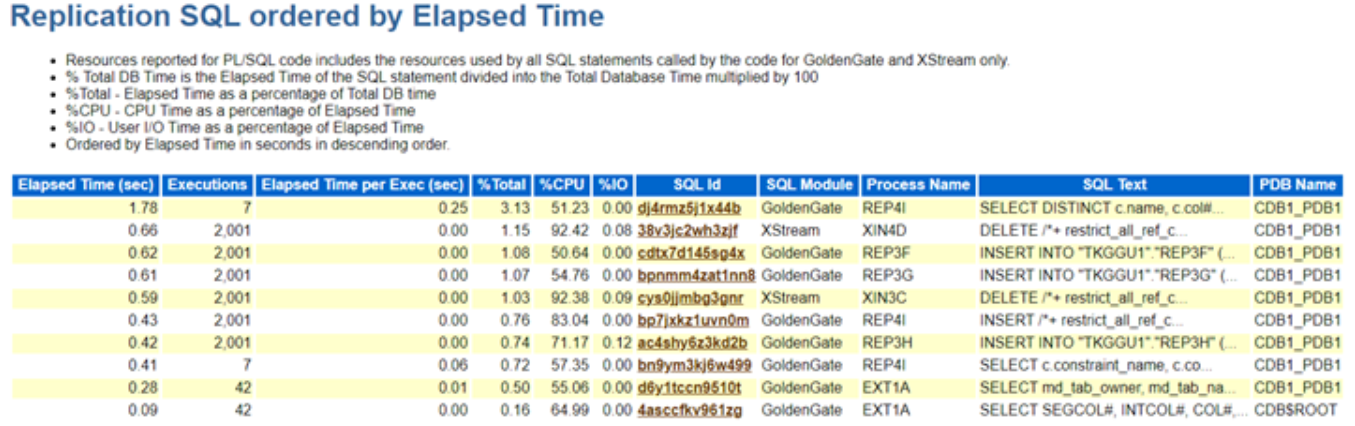
EXPLAIN gives you the plan as a flat table. It does not run the query. It’s fast, it’s compact, and it’s what you reach for 90% of the time. EXPLAIN FORMAT=JSON gives you the same plan with everything EXPLAIN had to leave out .. the actual cost numbers, which key parts were used, which columns get read, and the exact condition attached to each table. Still doesn’t run the query. When EXPLAIN says something confusing, this is where you go to find out why. EXPLAIN ANALYZE (8.0.18+) actually executes the query and reports what really happened alongside what was predicted. This is the one that ends arguments. It’s also the one you should think twice about before running against production on a DELETE— though for SELECTs it’s just a query that costs you its own runtime.
Same query, all three.
mysql> EXPLAIN SELECT c.email, o.amount FROM customers c
-> JOIN orders o ON o.customer_id = c.id
-> WHERE o.status = 'refunded' AND c.country = 'JP'\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: o
type: ref
possible_keys: ix_customer,ix_status
key: ix_status
key_len: 50
ref: const
rows: 2958
filtered: 100.00
Extra: NULL
*************************** 2. row ***************************
id: 1
select_type: SIMPLE
table: c
type: eq_ref
possible_keys: PRIMARY,ix_country
key: PRIMARY
key_len: 4
ref: shop.o.customer_id
rows: 1
filtered: 5.00
Extra: Using where
-- JSON format adds the details what were hidden
{
"query_block": {
"cost_info": { "query_cost": "3665.19" },
"nested_loop": [
{ "table": {
"table_name": "o",
"access_type": "ref",
"key": "ix_status",
"used_key_parts": ["status"],
"key_length": "50",
"rows_examined_per_scan": 2958,
"rows_produced_per_join": 2958,
"filtered": "100.00",
"cost_info": { "read_cost": "829.74", "eval_cost": "295.80",
"prefix_cost": "1125.54" }
}},
{ "table": {
"table_name": "c",
"access_type": "eq_ref",
"key": "PRIMARY",
"key_length": "4",
"ref": ["shop.o.customer_id"],
"rows_examined_per_scan": 1,
"rows_produced_per_join": 147,
"filtered": "5.00",
"cost_info": { "prefix_cost": "3665.19" },
"attached_condition": "(`shop`.`c`.`country` = 'JP')"
}}
]
}
}
prefix_cost is cumulative … 1125.54 after the first table, 3665.19 after both. rows_produced_per_join: 147 is the estimate flowing out of the join. attached_condition shows you exactly what’s being evaluated where, which is worth the verbosity all by itself. And now comes the truth time 🙂
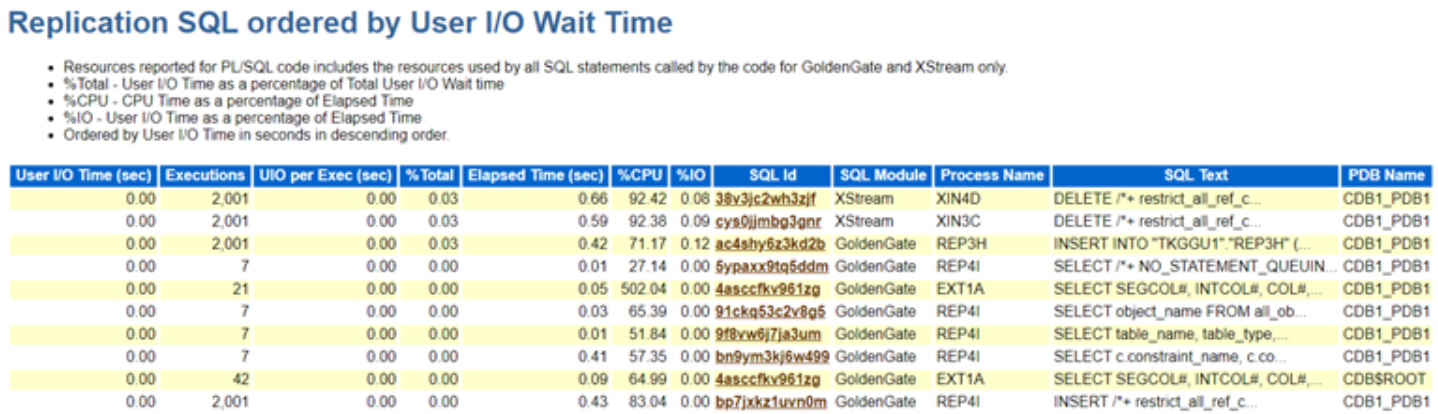
mysql> EXPLAIN ANALYZE SELECT c.email, o.amount FROM customers c
-> JOIN orders o ON o.customer_id = c.id
-> WHERE o.status = 'refunded' AND c.country = 'JP'\G
-> Nested loop inner join (cost=4286 rows=148) (actual time=1.18..37.4 rows=56 loops=1)
-> Index lookup on o using ix_status (status='refunded')
(cost=1035 rows=2958) (actual time=0.826..11.5 rows=2958 loops=1)
-> Filter: (c.country = 'JP')
(cost=0.999 rows=0.05) (actual time=0.00866..0.00866 rows=0.0189 loops=2958)
-> Single-row index lookup on c using PRIMARY (id=o.customer_id)
(cost=0.999 rows=1) (actual time=0.00842..0.00844 rows=1 loops=2958)
Read that inner block carefully, because it’s the single most misread thing in MySQL. rows=0.0189 loops=2958 does not mean MySQL found 0.0189 rows. It means the inner side was executed 2,958 times, and averaged 0.0189 rows per execution. Multiply: 0.0189 × 2958 ≈ 56, which is exactly the final row count. Same for timing … actual time=0.00866 is per loop, not total. The total time for that operation is roughly 0.00866 × 2958 ≈ 25ms. Estimated 148 rows, got 56. That’s a 2.6× overestimate, and I’ll come back to where it came from.
Next, lets check all of the columns and values used in the plan and what exact that means..
id : which SELECT this row belongs to. Same number across rows means same query block, and the order those rows appear in is the join order. Different numbers mean subqueries or unions, and a bigger id executes first.
select_type : SIMPLE for a plain query, PRIMARY for the outer part of one with subqueries, SUBQUERY, DERIVED, UNION, MATERIALIZED. If you see DEPENDENT SUBQUERY, tense up: it means the subquery reruns for every outer row.
table : the table, or a synthetic name like <derived2> for a derived table.
type : The access method. Most important column in the output; full section below.
possible_keys : indexes the optimizer considered. NULL here is diagnostic: it means no index could even theoretically serve this predicate, so before you tune anything, go look at whether the right index exists at all.
key : what it actually chose. When possible_keys lists three indexes and key picks one, the other two lost on cost. That’s a decision you can second-guess.
key_len : bytes of the index actually used. This is the column that catches partial index usage, and people ignore it because the calculation/maths looks like magic, but It isn’t:
- Each column’s base size (
INT= 4,BIGINT= 8) - +1 byte if the column is NULLable
- For variable-length strings, +2 bytes for the length prefix
- Character columns are counted in bytes, not characters — under
utf8mb4that’s 4 bytes per character
Check it against our real output. status is VARCHAR(12) NOT NULL under utf8mb4: 12 × 4 = 48 octets, no null byte, +2 for the length prefix = 50. And EXPLAIN reports key_len: 50. Exactly. ix_country on CHAR(2) gives 2 × 4 = 8, and yes, key_len: 8.
I built a throwaway table to prove the NULL byte is real …
INT NULL -> key_len: 5 (4 + 1 null byte)
INT NOT NULL -> key_len: 4
VARCHAR(10) NULL -> key_len: 43 (10*4 + 1 + 2)
Why care? Because on a composite index (a, b, c), key_len tells you how many of those columns are actually doing work. If key_len only accounts for a, then b and c are dead weight for this query and you’ve been fooling yourself about your index.
ref : what’s being compared against the indexed column. const for a literal, or a column name like shop.o.customer_id when the value comes from an earlier table in the join. This is how you read the data flow of a nested loop.
rows : estimated rows examined for this step. Estimated, and in a join it’s per iteration, not total.
filtered : percentage of those rows expected to survive the WHERE conditions that weren’t handled by the index. This is the column everyone skips and shouldn’t, because rows × filtered / 100 is what actually flows to the next table. In the join above, table c shows rows: 1, filtered: 5.00 … MySQL believes 5% of customers are in Japan. It isn’t 5%. There are eight countries in my data and JP is the rarest at about 2%. That 5.00 is a guess, and it’s precisely why the join estimate came out at 148 instead of 56.
Extra — everything else, and where the real diagnoses live.
Access types, which is best and the worst ??
const : at most one row, matched on a primary key or unique index against a literal. MySQL reads it once during optimization and substitutes it as a constant. You cannot do better.
EXPLAIN SELECT email FROM customers WHERE id = 42;
type: const key: PRIMARY key_len: 4 ref: const rows: 1
eq_ref : one row from this table per row from the previous table, via PK or unique index. This is the ideal for the driven side of a join, and it’s what our join got:
type: eq_ref key: PRIMARY key_len: 4 ref: shop.o.customer_id rows: 1
ref : A non-unique index lookup, may return many rows. Perfectly healthy. Our status='refunded' lookup is ref with rows: 2958.
range : index scan over a bounded range. BETWEEN, >, IN (...), LIKE 'foo%'.
EXPLAIN SELECT id FROM orders WHERE id BETWEEN 100 AND 500;
type: range key: PRIMARY key_len: 8 rows: 401 Extra: Using where; Using index
401 estimated, 401 actual. B-tree dives are good at this.
index : full scan of the entire index. Not a lookup. It’s ALL wearing a nicer coat, and it’s only cheap because the index is narrower than the table:
EXPLAIN SELECT COUNT(country) FROM customers;
type: index key: ix_country rows: 199488 Extra: Using index
ALL : Is a full table scan. Every row, from disk.
EXPLAIN SELECT * FROM orders WHERE amount > 500;
type: ALL possible_keys: NULL key: NULL rows: 997152 filtered: 33.33
Note: possible_keys: NULL : there’s no index on amount, so this was never even a contest. And note rows: 997152 when the table holds exactly 1,000,000 rows. InnoDB’s row count is itself an estimate, sampled, not counted. Don’t trust it to the digit. A full scan is not automatically a bug, by the way. If you’re reading 98% of the table, a scan genuinely is cheaper than a million index lookups each followed by a random row fetch. The bug is a full scan on a selective predicate.
Now lets read ‘EXTRA’:
Using index : a covering index. Everything the query needs lives in the index; the table itself is never touched. This is the single biggest win available in the Extra column, and it’s easy to engineer. Watch this ..
-- before
EXPLAIN SELECT customer_id, status FROM orders WHERE status='refunded';
type: ref key: ix_status rows: 2958 Extra: NULL
ALTER TABLE orders ADD INDEX ix_status_cust (status, customer_id);
-- after
type: ref key: ix_status_cust rows: 2958 Extra: Using index
Same rows, same access type, but Extra flipped to Using index and we eliminated 2,958 random primary-key lookups.
Using where : MySQL is filtering rows after fetching them from the storage engine. Not fatal on its own. But Using where sitting next to type: ALL and a low filtered is the classic missing-index signature.
Using index condition : Index Condition Pushdown. Different from Using index, and the names are unhelpfully similar. ICP means the condition is evaluated at the index level so non-matching entries never trigger a row fetch. It’s a real optimization, not a warning.
Using temporary : an internal temp table was built, usually for GROUP BY or DISTINCT. In 8.0 it’s TempTable in memory up to temptable_max_ram (default 1GB), then spills to disk. Small ones are fine. Big ones are why your query fell off a cliff.
Using filesort : the results had to be sorted, because no index provided the required order. “Filesort” does not mean it hit disk; it may well sort entirely in memory within sort_buffer_size. Bad name, causes endless confusion. Still, it’s work you might be able to design away with the right index.
Both at once, which is the combination worth hunting for:
EXPLAIN SELECT c.country, SUM(o.amount) t
FROM customers c JOIN orders o ON o.customer_id = c.id
WHERE o.status = 'pending'
GROUP BY c.country ORDER BY t DESC;
table: o type: ref key: ix_status rows: 22536
Extra: Using temporary; Using filesort
The GROUP BY builds the temp table, and the ORDER BY SUM(o.amount) forces the filesort on top of it .. you cannot index your way out of ordering by an aggregate that doesn’t exist until the group is computed. Sometimes the answer is “this is inherent, accept it.” Knowing which it is, is the job.
Scenario one: the cardinality trap (and where the usual advice is wrong)
Here’s where I have to correct something I’ve written myself in the past.
The standard story goes: MySQL assumes uniform distribution, so on a skewed column it wildly misestimates, and histograms fix it. Let’s test that. Two queries, same column, wildly different selectivity:
-- refunded: 2,958 rows, 0.296% of table
type: ref key: ix_status rows: 2958 filtered: 100.00
-- shipped: 980,123 rows, 98% of table
type: ref key: ix_status rows: 498576 filtered: 100.00
For refunded, rows: 2958 :: the exact true count. Not close. Exact. So much for uniform-distribution assumptions. This is records_in_range() diving into the B-tree and counting for real. But look at shipped: estimated 498,576, and EXPLAIN ANALYZE reports the truth:
-> Index lookup on orders using ix_status (status='shipped')
(cost=52812 rows=498576) (actual time=2.35..2136 rows=980123 loops=1)
980,123 actual against 498,576 estimated. A 1.97× underestimate … on the unselective value, not the selective one. The dive samples a bounded number of pages; over a huge range it extrapolates, and extrapolation drifts. So, surely a histogram fixes it?
ANALYZE TABLE orders UPDATE HISTOGRAM ON status WITH 16 BUCKETS;
-- re-run, WITH histogram in place
type: ref key: ix_status rows: 498576 filtered: 100.00
Nothing changed. Identical estimate. This is the finding I did not expect, and it’s the most useful thing in this post: when a usable index exists, the index dive wins and the histogram is ignored for the rows estimate.m Histograms feed filtered, not rows. To see them work, take the index away:
-- ix_status dropped
type: ALL possible_keys: NULL rows: 997152 filtered: 0.30 Extra: Using where
-> Filter: (orders.status = 'refunded') (cost=100912 rows=2949)
(actual time=0.83..251 rows=2958 loops=1)
-> Table scan on orders (cost=100912 rows=997152)
(actual time=0.738..200 rows=1e+6 loops=1)
filtered: 0.30 against a true 0.296%. Estimated 2,949 rows, actual 2,958. The histogram is superb — but only where the optimizer had nothing better.
The practical rule, then, is the opposite of the folklore. Build histograms on columns you are filtering on but have not indexed … typically because they’re low-cardinality and an index would be pointless, but they still need a decent filtered estimate to drive join ordering. Indexing the column and histogramming it is mostly wasted effort. One more trap while we’re in here. Look at the stored histogram:
"buckets": [
["base64:type254:Y2FuY2VsbGVk", 0.004594302009347028],
["base64:type254:cGVuZGluZw==", 0.01689858210334539],
["base64:type254:cmVmdW5kZWQ=", 0.019855833971430835],
["base64:type254:c2hpcHBlZA==", 1.0]
],
"histogram-type": "singleton",
"sampling-rate": 0.07373942163752957
Those are cumulative frequencies, not per-value. refunded is not 1.98% of the table … it’s 0.0199 − 0.0169 = 0.0030, i.e. 0.30%. The per-value frequency is the difference between consecutive buckets. I have watched people read that 1.0 on shipped and conclude the histogram is broken. And while we’re looking at bad statistics, check what InnoDB thinks ix_status contains:
INDEX_NAME COLUMN_NAME CARDINALITY
ix_status status 3
ix_customer customer_id 197646
PRIMARY id 997152
Cardinality 3. There are four distinct statuses. The default 20 page sample (innodb_stats_persistent_sample_pages) missed one entirely. If you have a low-cardinality column with a rare value that matters, raise that setting for the table and re-analyze … otherwise the optimizer is reasoning about a value it doesn’t know exists.
Scenario two: join order, and why it’s the whole game
Nested-loop joins have a brutal asymmetry: the driving table’s row count becomes the loop count for everything after it. Get it backwards and you multiply your own pain. MySQL got our join right. It drove from orders (2,958 refunded rows) and probed customers by primary key:
-> Nested loop inner join (cost=4286 rows=148) (actual time=1.18..37.4 rows=56 loops=1)
-> Index lookup on o using ix_status (status='refunded')
(cost=1035 rows=2958) (actual ... rows=2958 loops=1)
-> Filter: (c.country = 'JP')
(cost=0.999 rows=0.05) (actual ... rows=0.0189 loops=2958)
2,958 loops. 37.4ms. …. Now let’s force the mistake with STRAIGHT_JOIN, which pins join order to the order you wrote:
-> Nested loop inner join (cost=7692 rows=202) (actual time=1.2..93.1 rows=56 loops=1)
-> Index lookup on c using ix_country (country='JP')
(cost=920 rows=4039) (actual ... rows=4039 loops=1)
-> Filter: (o.status = 'refunded')
(cost=1.2 rows=0.05) (actual ... rows=0.0139 loops=4039)
-> Index lookup on o using ix_customer (customer_id=c.id)
(cost=1.2 rows=4.79) (actual ... rows=5.03 loops=4039)
4,039 loops. 93.1ms. Identical 56 rows out, two and a half times the time. And the inner side is worse than the loop count suggests: each of those 4,039 loops now fetches ~5 orders and throws nearly all of them away (rows=5.03 in, rows=0.0139 surviving the filter). We’re reading roughly 20,000 order rows to keep 56.
The optimizer picked correctly here. It doesn’t always … and when it doesn’t, the reason is almost always upstream: a filtered percentage built on a guess. Recall that filtered: 5.00 on customers. MySQL had no histogram on country, so it fell back to a canned guess, and that guess is what produced the 148-row estimate against 56 actual. On this query the error was harmless. On a five-table join, an error like that at step one compounds through every subsequent step, and that is how you get a plan that’s wrong by four orders of magnitude. While we’re here: filtered: 33.33 on the amount > 500 scan earlier is the same phenomenon in its purest form. That number is not measured. It’s MySQL’s hardcoded 1/3 guess for a range condition on a column it knows nothing about. Any time you see 33.33, 11.11, or 5.00 in filtered, you are looking at a guess, not a statistic.
Selecting and validating indexes
Start with the predicate, not the query text. Equality columns go first in a composite index, then range columns, then columns needed only for ORDER BY or covering. The reason is mechanical: a B tree can only use one range column before the ordering breaks down for everything to its right.
Check key_len to confirm the index is being used as far as you think it is. If your index is (status, customer_id, created_at) and key_len comes back as 50, only status is doing work.
Aim for Using index in Extra where you can. Adding one column to an existing index to make it covering is often a bigger win than adding a whole new index … and it costs you far less on write throughput.
Then validate with EXPLAIN ANALYZE, and compare estimated against actual. A ratio inside about 10× is usually fine. Beyond that, ask why: stale stats (run ANALYZE TABLE), a sample too small to see your rare values (raise innodb_stats_persistent_sample_pages), or a filtered built on a guess (histogram the column … as long as it isn’t already indexed).
Finally, resist the urge to just add the index. Every index is a write tax on every INSERT, UPDATE, and DELETE against that table, forever. Before you create one, check sys.schema_unused_indexes and sys.schema_redundant_indexes … I have never once run those on a mature production system and not found something to drop.
So, in short, summary, EXPLAIN tells you the plan. FORMAT=JSON tells you the costs behind it. EXPLAIN ANALYZE tells you the truth, and the truth is the only one of the three you can act on with confidence. Read rows and filtered together, always, because rows × filtered / 100 is what actually flows downstream. Treat loops as a multiplier, and remember that rows= and actual time= on an inner node are per loop. And when filtered shows you 33.33 or 5.00, recognise it for what it is: MySQL shrugging.
Then go and check whether the optimizer’s guess matched reality. Usually it does. The eleven-second query is where it didn’t.
Hope It Helped!
Prashant Dixit