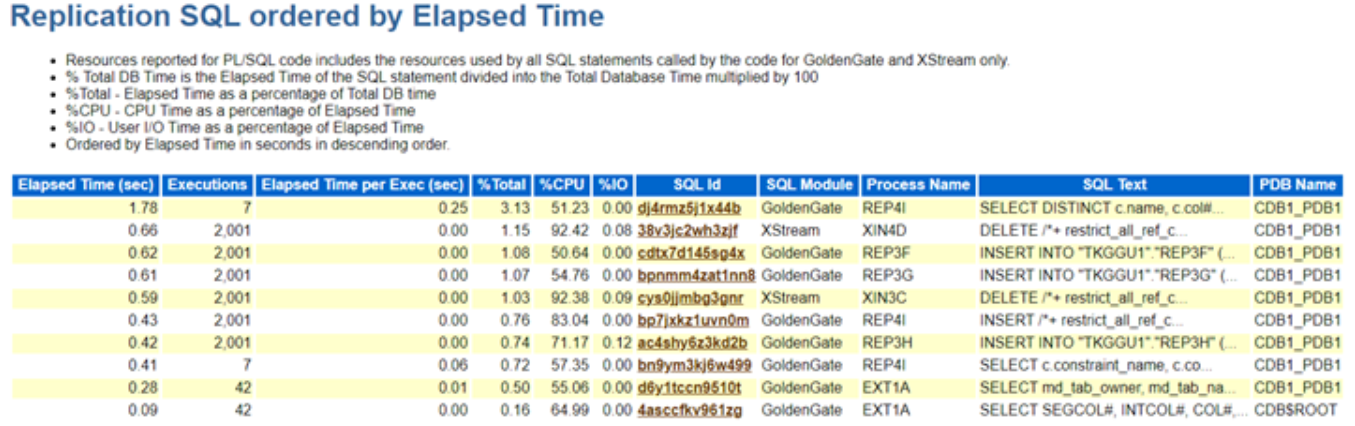
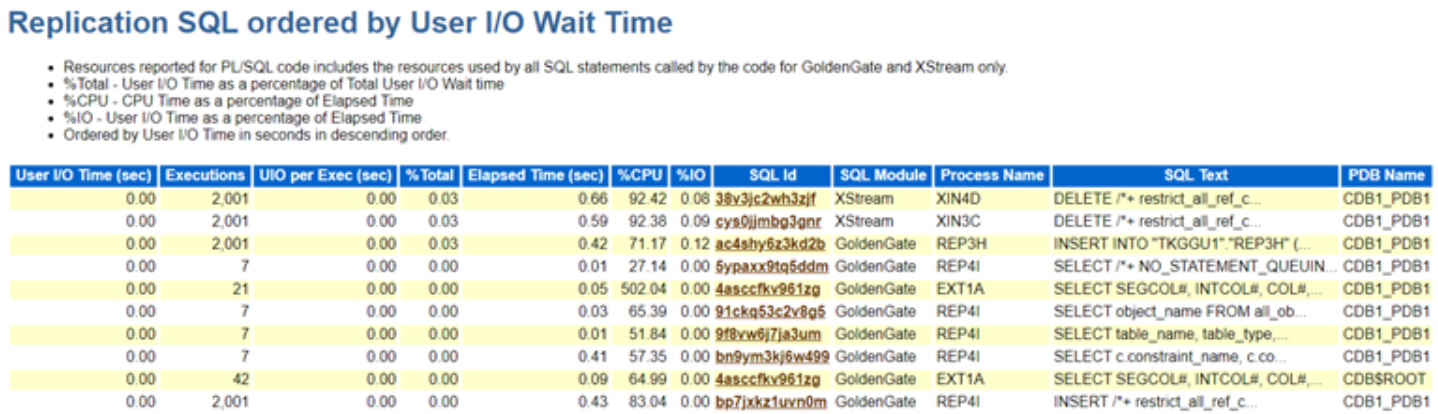
Migrations can be a horrifying experience —tricky, complex, time-intensive, and often riddled with unexpected challenges. This becomes even more evident when you’re migrating between older database versions, where architectural and component-level changes are significant. I remember one such encounter during a migration from Oracle 11g to 19c on a new infrastructure. Using RMAN DUPLICATE with the NOOPEN clause to restore source database backup in target before calling manual upgrade procedures, the process seemed smooth initially but soon wrapped into a host of issues with key database components.
The Problem
During the upgrade process, several critical components failed, leaving the database in an inconsistent state. The errors revolved around the following components:
| COMP_ID | COMP_NAME | VERSION | STATUS |
|---|---|---|---|
| JAVAVM | JServer JAVA Virtual Machine | 11.2.0.4.0 | UPGRADING |
| XML | Oracle XDK | 19.0.0.0.0 | INVALID |
| CATJAVA | Oracle Database Java Packages | 19.0.0.0.0 | INVALID |
The errors observed in dbupgrade runtime logs included:
ORA-29554: unhandled Java out of memory condition
ORA-06512: at "SYS.INITJVMAUX", line 230
ORA-06512: at line 5
ORA-06512: : at "SYS.INITJVMAUX", line 230 ORA-06512: at line 5
[ORA-29548: Java system class reported: release of Java system classes in the database (11.2.0.4.190115) does not match that of the oracle executable (19.0.0.0.0 1.8)
These errors stemmed from a failure to allocate sufficient memory during the upgrade process. The Java Virtual Machine (JVM) ran out of memory, causing cascading errors that invalidated other components like Oracle XDK and Java Database Packages (CATJAVA). This wasn’t a mere inconvenience—it meant that critical database functionality was broken, making the system unusable for applications relying on these components.
Root Cause
Upon investigation, we found that the issue was caused by using a temporary RMAN parameter file during the restore process. This parameter file contained a minimal set of initialization parameters, which were insufficient to handle the resource-intensive operations required during the upgrade, particularly for recompiling and validating Java components.
Key memory areas like the SGA, shared pool, large pool, and Java pool were inadequately configured. These areas play a crucial role during the execution of upgrade scripts such as dbupgrade, catctl.pl, or catupgrd.sql. Without sufficient memory, the upgrade process for these components failed midway, leaving them in an invalid state.
The Fix
To resolve these issues and ensure the migration proceeded smoothly, the following steps were taken:
Step 1: Adjust Initialization Parameters
The first step was to allocate adequate memory for the Java components to prevent out-of-memory conditions. Critical parameters like the Java pool and other memory pools were adjusted to handle the load during the upgrade process:
ALTER SYSTEM SET java_jit_enabled = TRUE;
ALTER SYSTEM SET "_system_trig_enabled" = TRUE;
ALTER SYSTEM SET java_pool_size = 180M; -- Ensure at least 150 MB is allocated
Step 2: Recreate the Java Component
The next step was to drop and recreate the Java component in the database. This ensured that any inconsistencies caused by the previous upgrade failure were cleaned up:
CREATE OR REPLACE JAVA SYSTEM;
Step 3: Restart the Upgrade Scripts
After fixing the memory settings and recreating the Java component, the upgrade process was restarted using Oracle’s upgrade utilities:
dbupgrade: The recommended tool for 19c migrations.catctl.pl: For manual control over the upgrade process.catupgrd.sql: A fallback script for older methods.
Logs such as upg_summary.log were closely monitored during the process to catch any errors or exceptions in real-time.
Step 4: Verify the Upgrade
Once the upgrade process was completed, the status of all components was verified using the DBA_REGISTRY and DBA_REGISTRY_HISTORY views:
SELECT SUBSTR(comp_name, 1, 30) comp_name,
SUBSTR(version, 1, 20) version,
status
FROM dba_registry
ORDER BY comp_name;
Expected output:
COMP_NAME VERSION STATUS
------------------------------ -------------------- ---------------
JServer JAVA Virtual Machine 19.0.0.0.0 UPGRADED
Key Takeaways
This experience highlighted several crucial lessons when handling database migrations, especially for major version upgrades like 11g to 19c:
1. Adequate Initialization Parameters Are Essential
The memory-related initialization parameters (java_pool_size, shared_pool_size, etc.) must be configured appropriately before starting the upgrade process. Using a minimal parameter file during RMAN DUPLICATE can lead to critical issues if not adjusted later.
2. Resource-Intensive Components Need Extra Attention
Components like JAVAVM, Oracle XDK, and CATJAVA are highly resource-intensive. Even slight memory misconfigurations can lead to cascading failures that disrupt the entire migration process.
3. Monitor Upgrade Logs Closely
Keeping an eye on upgrade runtime logs and the summary logs (upg_summary.log) is vital for catching errors early. This allows you to address issues promptly before they snowball into larger problems.
4. Understand Dependencies
Database components often have interdependencies. For instance, a failure in the Java Virtual Machine component affected both the Oracle XDK and CATJAVA packages. Understanding these dependencies is key to resolving issues effectively.
Conclusion
Database migrations are inherently challenging, especially when dealing with major version jumps. This particular experience from migrating Oracle 11g to 19c served as a valuable reminder of the importance of preparation, thorough testing, and paying close attention to resource configurations. With the right approach, even complex migrations can be navigated successfully, ensuring the database is ready for modern workloads and enhanced performance.
By addressing these pitfalls and being proactive, you can ensure a smoother upgrade process and avoid unnecessary downtime or functionality issues.
Let me know if this approach resonates with your migration experiences!
Hope It Helped!
Prashant Dixit