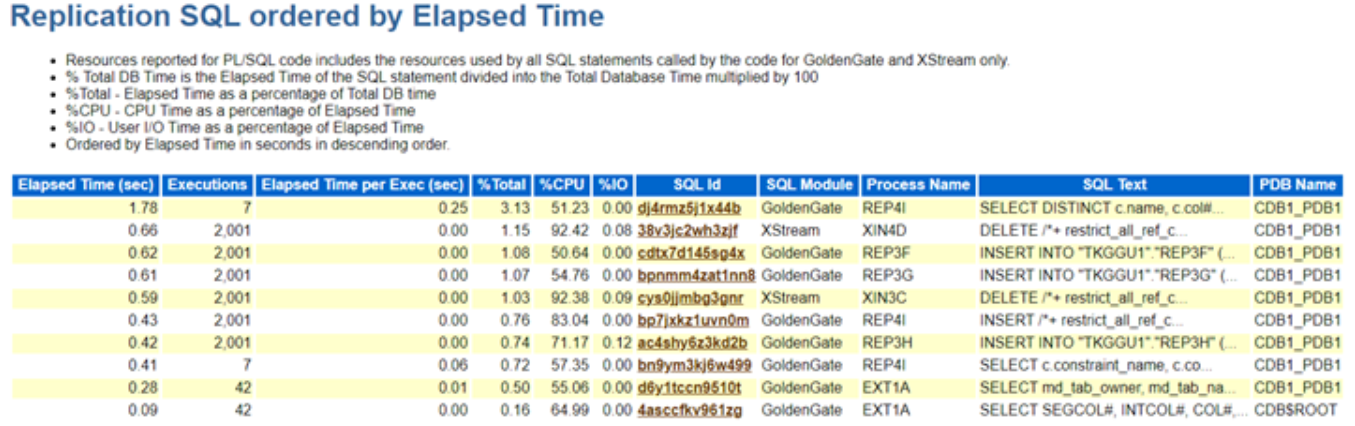
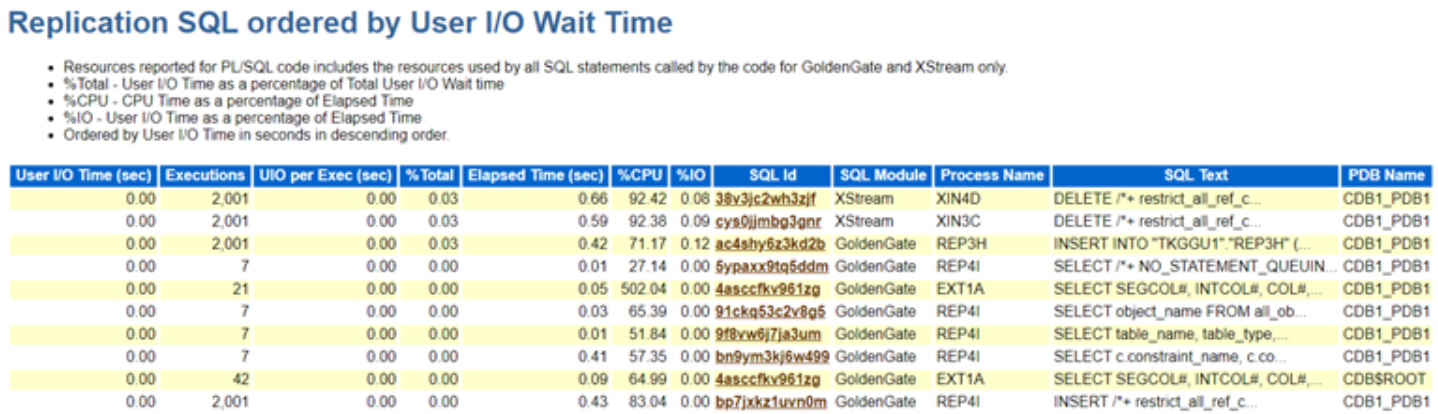
So Oracle rolled out 23ai a while back and like every major release, it came packed with some really cool and interesting features. One that definitely caught my eye was Vector Search. I couldn’t resist diving in… and recently I explored it in depth and would like to share a though on this subject.
You see, we’ve been doing LIKE '%tax policy%' since forever. But now, Oracle’s SQL has become more powerful. Not only does it match words … it matches meaning.
So here’s me trying to explain what vector search is, how Oracle does it, why you’d care, and some examples that’ll hopefully make it click.
What’s Vector Search, Anyway?
Alright, imagine this:
You have a table of products. You search for “lightweight laptop for travel”.
Some entries say “ultrabook”, others say “portable notebook”, and none mention “lightweight” or “travel”. Old-school SQL would’ve said: “No Matches Found”
But with vector search, it gets it. Oracle turns all that text into math .. basically, a long list of numbers called a vector … and compares meanings instead of words.
So What’s a Vector?
When we say “vector” in vector search, we’re not talking about geometry class. In the world of AI and databases, a vector is just a long list of numbers … each number representing some aspect or feature of the original input (like a sentence, product description, image, etc.).
Here’s a basic example:
[0.12, -0.45, 0.88, …, 0.03]
This is a vector … maybe a 512 or 1536-dimension one .. depending on the embedding model used (like OpenAI, Oracle’s built-in model, Cohere, etc.).
Each number in this list is abstract, but together they represent the essence or meaning of your data.
Let’s say you have these two phrases:
“Apple is a tech company”
“iPhone maker based in California”
Now, even though they don’t share many words, they mean nearly the same thing. When passed through an embedding model, both phrases are converted into vectors:
Vector A: [0.21, -0.32, 0.76, …, 0.02]
Vector B: [0.22, -0.30, 0.74, …, 0.01]
They look very close … and that’s exactly the point.
What Oracle 23ai Gives You
- A new VECTOR datatype (yeah!)
AI_VECTOR()function to convert text into vectorsVECTOR_INDEXto make search blazing fastVECTOR_DISTANCE()to measure similarity- It’s all native in SQL ..no need for another vector DB bolted on
Let’s Build Something Step-by-Step
We’ll build a simple product table and do a vector search on it.
Step 1: Create the table
CREATE TABLE products (
product_id NUMBER PRIMARY KEY,
product_name VARCHAR2(100),
description VARCHAR2(1000),
embedding VECTOR(1536)
);
1536? Yeah, that’s the number of dimensions from Oracle’s built-in embedding model. Depends on which one you use.
Step 2: Generate vector embeddings
UPDATE products
SET embedding = ai_vector('text_embedding', description);
This’ll take the description, pass it through Oracle’s AI model, and give you a vector. Magic.
Step 3: Create the vector index
CREATE VECTOR INDEX product_vec_idx
ON products (embedding)
WITH (DISTANCE METRIC COSINE);
This speeds up the similarity comparisons … much like an index does for normal WHERE clauses.
Step 4: Semantic Search in SQL
SELECT product_id, product_name,
VECTOR_DISTANCE(embedding, ai_vector('text_embedding', 'light laptop for designers')) AS score
FROM products
ORDER BY score
FETCH FIRST 5 ROWS ONLY;
Now we’re searching for meaning, not words.
VECTOR_DISTANCE Breakdown
You can use different math behind the scenes:
VECTOR_DISTANCE(v1, v2 USING COSINE)
VECTOR_DISTANCE(v1, v2 USING EUCLIDEAN)
VECTOR_DISTANCE(v1, v2 USING DOT_PRODUCT)
Cosine is the usual go-to for text. Oracle handles the rest for you.
Use Cases You’ll Actually Care About
1. Semantic Product Search — “Fast shoes for runners” => shows “Nike Vaporfly”, even if it doesn’t say “fast”.
2. Similar Document Retrieval — Find all NDAs that look like this one (even with totally different words).
3. Customer Ticket Suggestion — Auto-suggest resolutions from past tickets. Saves your support team hours.
4. Content Recommendation — “People who read this also read…” kind of stuff. Easy to build now.
5. Risk or Fraud Pattern Matching — Find transactions that feel like fraud ..even if the details don’t match 1:1.
I know it might sound little confusing .. lets do a Onwe more example : Legal Document Matching
CREATE TABLE legal_docs (
doc_id NUMBER PRIMARY KEY,
title VARCHAR2(255),
content CLOB,
content_vec VECTOR(1536)
);
Update vectors:
UPDATE legal_docs
SET content_vec = ai_vector('text_embedding', content);
Now find similar docs:
SELECT doc_id, title
FROM legal_docs
ORDER BY VECTOR_DISTANCE(content_vec, ai_vector('text_embedding', 'confidentiality in government contracts'))
FETCH FIRST 10 ROWS ONLY;
That’s it. You’re officially building an AI-powered legal search engine.
Things to Know
- Creating vectors can be heavy .. batch it.
- Indexing speeds up similarity search a lot.
- Combine with normal filters for best results:
SELECT * FROM products
WHERE category = 'laptop'
ORDER BY VECTOR_DISTANCE(embedding, ai_vector('gaming laptop under 1kg'))
FETCH FIRST 5 ROWS ONLY;
Final Thoughts from fatdba
I’m honestly impressed. Oracle took something that felt like ML black magic and put it right in SQL. No external service. No complicated setups. Just regular SQL, but smater.
Hope It Helped!
Prashant Dixit
Database Architect @RENAPS
Reach us at : https://renaps.com/