He has a demo/POC that he needs to do for one of his customer who is interested to see how it looks like in reality and how ‘deadly’ is the problem and how to fix this. He scanned almost everything on the Google, but unfortunately found nothing available or pre-cooked …
We will open multiple parallel sessions to simulate the workload and monitor the progress.
Now, I will create a file with current transaction ID written in to it and will call the pgbench. I am doing something like below to call pgbench, below are the explanations on flags used and why I used them ..
-bash-4.2$
-bash-4.2$ echo 'select txid_current();' > wl.sql
-bash-4.2$
-bash-4.2$
-bash-4.2$ /usr/edb/as11/bin/pgbench -U enterprisedb enterprisedb -f wl.sql -c8 -j8 -T100000 -rn -P60
progress: 60.0 s, 51097.6 tps, lat 0.157 ms stddev 0.262
progress: 120.0 s, 51171.1 tps, lat 0.156 ms stddev 0.252
progress: 180.0 s, 51622.8 tps, lat 0.155 ms stddev 0.250
progress: 240.0 s, 51328.9 tps, lat 0.156 ms stddev 0.260
progress: 300.0 s, 50976.6 tps, lat 0.157 ms stddev 0.256
progress: 360.0 s, 51130.3 tps, lat 0.156 ms stddev 0.265
progress: 420.0 s, 50792.6 tps, lat 0.158 ms stddev 0.254
progress: 480.0 s, 51207.2 tps, lat 0.156 ms stddev 0.250
progress: 540.0 s, 51162.6 tps, lat 0.156 ms stddev 0.251
progress: 600.0 s, 51246.0 tps, lat 0.156 ms stddev 0.256
progress: 660.0 s, 51047.3 tps, lat 0.157 ms stddev 0.253
progress: 720.0 s, 51197.3 tps, lat 0.156 ms stddev 0.252
progress: 780.0 s, 51119.2 tps, lat 0.156 ms stddev 0.281
progress: 840.0 s, 50938.8 tps, lat 0.157 ms stddev 0.252
progress: 900.0 s, 51252.8 tps, lat 0.156 ms stddev 0.251
progress: 960.0 s, 51054.0 tps, lat 0.157 ms stddev 0.253
progress: 1020.0 s, 51159.5 tps, lat 0.156 ms stddev 0.254
progress: 1080.0 s, 51116.0 tps, lat 0.157 ms stddev 0.253
progress: 1140.0 s, 50947.6 tps, lat 0.157 ms stddev 0.251
progress: 1200.0 s, 51289.7 tps, lat 0.156 ms stddev 0.254
progress: 1260.0 s, 50338.7 tps, lat 0.159 ms stddev 0.254
progress: 1320.0 s, 50121.1 tps, lat 0.160 ms stddev 0.260
progress: 1380.0 s, 49936.6 tps, lat 0.160 ms stddev 0.291
progress: 1440.0 s, 50451.1 tps, lat 0.159 ms stddev 0.251
progress: 1500.0 s, 51107.4 tps, lat 0.157 ms stddev 0.248
progress: 1560.0 s, 50907.8 tps, lat 0.157 ms stddev 0.321
progress: 1620.0 s, 51033.7 tps, lat 0.157 ms stddev 0.251
progress: 1680.0 s, 51013.6 tps, lat 0.157 ms stddev 0.254
progress: 1740.0 s, 51119.4 tps, lat 0.156 ms stddev 0.252
progress: 1800.0 s, 51411.9 tps, lat 0.156 ms stddev 0.249
progress: 1860.0 s, 51099.1 tps, lat 0.157 ms stddev 0.249
progress: 1920.0 s, 51527.5 tps, lat 0.155 ms stddev 0.256
progress: 1980.0 s, 51204.3 tps, lat 0.156 ms stddev 0.267
progress: 2040.0 s, 51363.8 tps, lat 0.156 ms stddev 0.249
progress: 2100.0 s, 51563.1 tps, lat 0.155 ms stddev 0.250
progress: 2160.0 s, 51329.3 tps, lat 0.156 ms stddev 0.246
progress: 2220.0 s, 51073.4 tps, lat 0.157 ms stddev 0.276
progress: 2280.0 s, 51402.0 tps, lat 0.156 ms stddev 0.248
progress: 2340.0 s, 51364.4 tps, lat 0.156 ms stddev 0.253
progress: 2400.0 s, 50890.0 tps, lat 0.157 ms stddev 0.251
progress: 2460.0 s, 50239.6 tps, lat 0.159 ms stddev 0.296
progress: 2520.0 s, 50684.8 tps, lat 0.158 ms stddev 0.283
progress: 2580.0 s, 49826.2 tps, lat 0.161 ms stddev 0.271
progress: 2640.0 s, 51076.7 tps, lat 0.157 ms stddev 0.250
progress: 2700.0 s, 51349.6 tps, lat 0.156 ms stddev 0.252
progress: 2760.0 s, 51076.6 tps, lat 0.157 ms stddev 0.253
progress: 2820.0 s, 50854.5 tps, lat 0.157 ms stddev 0.256
progress: 2880.0 s, 49864.8 tps, lat 0.160 ms stddev 0.260
progress: 2940.0 s, 50450.1 tps, lat 0.159 ms stddev 0.264
progress: 3000.0 s, 50334.7 tps, lat 0.159 ms stddev 0.264
progress: 3060.0 s, 50514.3 tps, lat 0.158 ms stddev 0.299
progress: 3120.0 s, 50508.7 tps, lat 0.158 ms stddev 0.284
progress: 3180.0 s, 50691.3 tps, lat 0.158 ms stddev 0.288
progress: 3240.0 s, 50601.6 tps, lat 0.158 ms stddev 0.256
progress: 3300.0 s, 50280.2 tps, lat 0.159 ms stddev 0.264
progress: 3360.0 s, 50457.6 tps, lat 0.159 ms stddev 0.265
progress: 3420.0 s, 50178.3 tps, lat 0.159 ms stddev 0.390
progress: 3480.0 s, 50353.3 tps, lat 0.159 ms stddev 0.264
progress: 3540.0 s, 50133.0 tps, lat 0.160 ms stddev 0.259
progress: 3600.0 s, 50217.6 tps, lat 0.159 ms stddev 0.282
progress: 3660.0 s, 50147.8 tps, lat 0.160 ms stddev 0.279
progress: 3720.0 s, 50578.0 tps, lat 0.158 ms stddev 0.261
progress: 3780.0 s, 50523.9 tps, lat 0.158 ms stddev 0.261
progress: 3840.0 s, 50349.7 tps, lat 0.159 ms stddev 0.269
progress: 3900.0 s, 50437.5 tps, lat 0.159 ms stddev 0.287
progress: 3960.0 s, 49569.1 tps, lat 0.161 ms stddev 0.311
progress: 4020.0 s, 50337.3 tps, lat 0.159 ms stddev 0.286
progress: 4080.0 s, 50065.2 tps, lat 0.160 ms stddev 0.260
progress: 4140.0 s, 49791.4 tps, lat 0.161 ms stddev 0.264
progress: 4200.0 s, 49681.3 tps, lat 0.161 ms stddev 0.326
progress: 4260.0 s, 48034.2 tps, lat 0.167 ms stddev 0.340
progress: 4320.0 s, 50460.9 tps, lat 0.159 ms stddev 0.290
progress: 4380.0 s, 49731.0 tps, lat 0.161 ms stddev 0.300
progress: 4440.0 s, 50441.1 tps, lat 0.159 ms stddev 0.266
progress: 4500.0 s, 50259.1 tps, lat 0.159 ms stddev 0.267
progress: 4560.0 s, 50197.0 tps, lat 0.159 ms stddev 0.259
progress: 4620.0 s, 49832.1 tps, lat 0.161 ms stddev 0.271
progress: 4680.0 s, 50160.3 tps, lat 0.159 ms stddev 0.268
progress: 4740.0 s, 50578.5 tps, lat 0.158 ms stddev 0.262
progress: 4800.0 s, 50260.5 tps, lat 0.159 ms stddev 0.270
progress: 4860.0 s, 50545.1 tps, lat 0.158 ms stddev 0.256
progress: 4920.0 s, 49961.8 tps, lat 0.160 ms stddev 0.285
progress: 4980.0 s, 50450.7 tps, lat 0.159 ms stddev 0.267
progress: 5040.0 s, 50008.7 tps, lat 0.160 ms stddev 0.257
progress: 5100.0 s, 49723.2 tps, lat 0.161 ms stddev 0.428
progress: 5160.0 s, 50211.1 tps, lat 0.159 ms stddev 0.378
progress: 5220.0 s, 49791.0 tps, lat 0.161 ms stddev 0.262
progress: 5280.0 s, 50091.5 tps, lat 0.160 ms stddev 0.265
progress: 5340.0 s, 50280.3 tps, lat 0.159 ms stddev 0.266
progress: 5400.0 s, 49957.1 tps, lat 0.160 ms stddev 0.402
progress: 5460.0 s, 50101.7 tps, lat 0.160 ms stddev 0.293
progress: 5520.0 s, 50387.3 tps, lat 0.159 ms stddev 0.261
progress: 5580.0 s, 50173.2 tps, lat 0.159 ms stddev 0.278
progress: 5640.0 s, 50225.1 tps, lat 0.159 ms stddev 0.266
progress: 5700.0 s, 50186.7 tps, lat 0.159 ms stddev 0.264
progress: 5760.0 s, 49120.1 tps, lat 0.163 ms stddev 0.264
progress: 5820.0 s, 49445.3 tps, lat 0.162 ms stddev 0.262
progress: 5880.0 s, 49547.2 tps, lat 0.161 ms stddev 0.260
progress: 5940.0 s, 49730.2 tps, lat 0.161 ms stddev 0.267
progress: 6000.0 s, 50543.3 tps, lat 0.158 ms stddev 0.258
progress: 6060.0 s, 50569.1 tps, lat 0.158 ms stddev 0.258
progress: 6120.0 s, 50560.4 tps, lat 0.158 ms stddev 0.250
progress: 6180.0 s, 50572.1 tps, lat 0.158 ms stddev 0.255
progress: 6240.0 s, 50551.6 tps, lat 0.158 ms stddev 0.253
progress: 6300.0 s, 50993.8 tps, lat 0.157 ms stddev 0.254
progress: 6360.0 s, 51114.6 tps, lat 0.157 ms stddev 0.257
progress: 6420.0 s, 50762.6 tps, lat 0.158 ms stddev 0.261
progress: 6480.0 s, 50814.2 tps, lat 0.157 ms stddev 0.250
progress: 6540.0 s, 50735.7 tps, lat 0.158 ms stddev 0.257
progress: 6600.0 s, 50521.9 tps, lat 0.158 ms stddev 0.263
progress: 6660.0 s, 50829.8 tps, lat 0.157 ms stddev 0.252
progress: 6720.0 s, 50933.7 tps, lat 0.157 ms stddev 0.255
progress: 6780.0 s, 51152.9 tps, lat 0.156 ms stddev 0.252
progress: 6840.0 s, 50457.1 tps, lat 0.159 ms stddev 0.255
progress: 6900.0 s, 50542.5 tps, lat 0.158 ms stddev 0.251
progress: 6960.0 s, 50802.5 tps, lat 0.157 ms stddev 0.282
progress: 7020.0 s, 51066.1 tps, lat 0.157 ms stddev 0.270
progress: 7080.0 s, 50729.0 tps, lat 0.158 ms stddev 0.258
progress: 7140.0 s, 51242.7 tps, lat 0.156 ms stddev 0.255
progress: 7200.0 s, 50714.2 tps, lat 0.158 ms stddev 0.253
progress: 7260.0 s, 50704.7 tps, lat 0.158 ms stddev 0.323
progress: 7320.0 s, 50951.4 tps, lat 0.157 ms stddev 0.250
progress: 7380.0 s, 50604.8 tps, lat 0.158 ms stddev 0.340
progress: 7440.0 s, 51217.0 tps, lat 0.156 ms stddev 0.251
progress: 7500.0 s, 50832.4 tps, lat 0.157 ms stddev 0.251
progress: 7560.0 s, 50815.7 tps, lat 0.157 ms stddev 0.256
progress: 7620.0 s, 49936.3 tps, lat 0.160 ms stddev 0.463
progress: 7680.0 s, 50556.4 tps, lat 0.158 ms stddev 0.251
progress: 7740.0 s, 50699.8 tps, lat 0.158 ms stddev 0.255
progress: 7800.0 s, 50474.0 tps, lat 0.158 ms stddev 0.256
progress: 7860.0 s, 50401.9 tps, lat 0.159 ms stddev 0.321
progress: 7920.0 s, 51385.5 tps, lat 0.156 ms stddev 0.251
progress: 7980.0 s, 50671.9 tps, lat 0.158 ms stddev 0.248
progress: 8040.0 s, 50631.3 tps, lat 0.158 ms stddev 0.252
progress: 8100.0 s, 50741.3 tps, lat 0.158 ms stddev 0.255
progress: 8160.0 s, 50465.5 tps, lat 0.159 ms stddev 0.257
progress: 8220.0 s, 51384.9 tps, lat 0.156 ms stddev 0.212
progress: 8280.0 s, 51676.8 tps, lat 0.155 ms stddev 0.233
progress: 8340.0 s, 52049.3 tps, lat 0.154 ms stddev 0.179
progress: 8400.0 s, 52394.6 tps, lat 0.153 ms stddev 0.178
progress: 8460.0 s, 51872.3 tps, lat 0.154 ms stddev 0.192
progress: 8520.0 s, 51896.9 tps, lat 0.154 ms stddev 0.178
progress: 8580.0 s, 52187.5 tps, lat 0.153 ms stddev 0.178
progress: 8640.0 s, 51773.8 tps, lat 0.155 ms stddev 0.185
progress: 8700.0 s, 51862.7 tps, lat 0.154 ms stddev 0.184
progress: 8760.0 s, 51906.7 tps, lat 0.154 ms stddev 0.189
progress: 8820.0 s, 52038.6 tps, lat 0.154 ms stddev 0.189
progress: 8880.0 s, 52370.9 tps, lat 0.153 ms stddev 0.180
progress: 8940.0 s, 52155.2 tps, lat 0.153 ms stddev 0.185
progress: 9000.0 s, 52162.2 tps, lat 0.153 ms stddev 0.219
progress: 9060.0 s, 51900.7 tps, lat 0.154 ms stddev 0.189
progress: 9120.0 s, 51794.5 tps, lat 0.154 ms stddev 0.178
progress: 9180.0 s, 51885.1 tps, lat 0.154 ms stddev 0.180
progress: 9240.0 s, 52007.4 tps, lat 0.154 ms stddev 0.177
progress: 9300.0 s, 52168.3 tps, lat 0.153 ms stddev 0.189
progress: 9360.0 s, 51801.3 tps, lat 0.154 ms stddev 0.182
progress: 9420.0 s, 51899.8 tps, lat 0.154 ms stddev 0.173
progress: 9480.0 s, 52215.3 tps, lat 0.153 ms stddev 0.177
progress: 9540.0 s, 52129.9 tps, lat 0.153 ms stddev 0.227
progress: 9600.0 s, 51929.9 tps, lat 0.154 ms stddev 0.176
progress: 9660.0 s, 51776.6 tps, lat 0.155 ms stddev 0.181
progress: 9720.0 s, 51542.8 tps, lat 0.155 ms stddev 0.268
progress: 9780.0 s, 51352.5 tps, lat 0.156 ms stddev 0.310
progress: 9840.0 s, 51661.0 tps, lat 0.155 ms stddev 0.177
progress: 9900.0 s, 51219.8 tps, lat 0.156 ms stddev 0.260
progress: 9960.0 s, 52235.8 tps, lat 0.153 ms stddev 0.184
progress: 10020.0 s, 51904.5 tps, lat 0.154 ms stddev 0.186
progress: 10080.0 s, 52066.8 tps, lat 0.154 ms stddev 0.183
progress: 10140.0 s, 52212.5 tps, lat 0.153 ms stddev 0.209
progress: 10200.0 s, 52402.8 tps, lat 0.153 ms stddev 0.186
progress: 10260.0 s, 52194.8 tps, lat 0.153 ms stddev 0.178
progress: 10320.0 s, 52117.3 tps, lat 0.153 ms stddev 0.179
progress: 10380.0 s, 52060.5 tps, lat 0.154 ms stddev 0.181
progress: 10440.0 s, 52043.1 tps, lat 0.154 ms stddev 0.183
progress: 10500.0 s, 52358.5 tps, lat 0.153 ms stddev 0.178
progress: 10560.0 s, 51361.2 tps, lat 0.156 ms stddev 0.179
progress: 10620.0 s, 51655.7 tps, lat 0.155 ms stddev 0.184
progress: 10680.0 s, 51501.1 tps, lat 0.155 ms stddev 0.176
progress: 10740.0 s, 51315.4 tps, lat 0.156 ms stddev 0.182
progress: 10800.0 s, 52344.5 tps, lat 0.153 ms stddev 0.181
progress: 10860.0 s, 51687.0 tps, lat 0.155 ms stddev 0.182
progress: 10920.0 s, 51150.2 tps, lat 0.156 ms stddev 0.179
progress: 10980.0 s, 51341.9 tps, lat 0.156 ms stddev 0.181
progress: 11040.0 s, 51074.0 tps, lat 0.157 ms stddev 0.184
progress: 11100.0 s, 51645.4 tps, lat 0.155 ms stddev 0.277
progress: 11160.0 s, 51984.6 tps, lat 0.154 ms stddev 0.182
progress: 11220.0 s, 51993.4 tps, lat 0.154 ms stddev 0.181
progress: 11280.0 s, 51894.9 tps, lat 0.154 ms stddev 0.183
progress: 11340.0 s, 52007.2 tps, lat 0.154 ms stddev 0.186
progress: 11400.0 s, 52255.9 tps, lat 0.153 ms stddev 0.188
progress: 11460.0 s, 52221.2 tps, lat 0.153 ms stddev 0.183
progress: 11520.0 s, 51990.5 tps, lat 0.154 ms stddev 0.181
progress: 11580.0 s, 52138.3 tps, lat 0.153 ms stddev 0.178
progress: 11640.0 s, 51258.2 tps, lat 0.156 ms stddev 0.178
progress: 11700.0 s, 52268.0 tps, lat 0.153 ms stddev 0.179
progress: 11760.0 s, 51838.4 tps, lat 0.154 ms stddev 0.180
progress: 11820.0 s, 52079.2 tps, lat 0.154 ms stddev 0.185
progress: 11880.0 s, 52531.4 tps, lat 0.152 ms stddev 0.175
progress: 11940.0 s, 51711.7 tps, lat 0.155 ms stddev 0.260
progress: 12000.0 s, 52020.7 tps, lat 0.154 ms stddev 0.180
progress: 12060.0 s, 51990.1 tps, lat 0.154 ms stddev 0.241
progress: 12120.0 s, 51367.6 tps, lat 0.156 ms stddev 0.193
progress: 12180.0 s, 51316.0 tps, lat 0.156 ms stddev 0.187
progress: 12240.0 s, 50819.0 tps, lat 0.157 ms stddev 0.190
progress: 12300.0 s, 51614.6 tps, lat 0.155 ms stddev 0.182
progress: 12360.0 s, 51500.6 tps, lat 0.155 ms stddev 0.187
progress: 12420.0 s, 51715.8 tps, lat 0.155 ms stddev 0.259
progress: 12480.0 s, 51805.0 tps, lat 0.154 ms stddev 0.183
progress: 12540.0 s, 51846.2 tps, lat 0.154 ms stddev 0.183
progress: 12600.0 s, 51829.6 tps, lat 0.154 ms stddev 0.179
progress: 12660.0 s, 51411.1 tps, lat 0.156 ms stddev 0.221
progress: 12720.0 s, 51728.5 tps, lat 0.155 ms stddev 0.187
progress: 12780.0 s, 52170.5 tps, lat 0.153 ms stddev 0.181
progress: 12840.0 s, 51985.8 tps, lat 0.154 ms stddev 0.182
progress: 12900.0 s, 51723.3 tps, lat 0.155 ms stddev 0.181
progress: 12960.0 s, 52324.2 tps, lat 0.153 ms stddev 0.184
progress: 13020.0 s, 51795.5 tps, lat 0.154 ms stddev 0.189
progress: 13080.0 s, 51547.3 tps, lat 0.155 ms stddev 0.373
progress: 13140.0 s, 51592.4 tps, lat 0.155 ms stddev 0.231
progress: 13200.0 s, 52004.8 tps, lat 0.154 ms stddev 0.223
progress: 13260.0 s, 52118.3 tps, lat 0.153 ms stddev 0.184
progress: 13320.0 s, 51781.1 tps, lat 0.154 ms stddev 0.183
progress: 13380.0 s, 50621.8 tps, lat 0.158 ms stddev 0.196
progress: 13440.0 s, 50671.8 tps, lat 0.158 ms stddev 0.321
progress: 13500.0 s, 51389.4 tps, lat 0.156 ms stddev 0.181
progress: 13560.0 s, 51653.2 tps, lat 0.155 ms stddev 0.186
progress: 13620.0 s, 51491.7 tps, lat 0.155 ms stddev 0.181
progress: 13680.0 s, 51639.4 tps, lat 0.155 ms stddev 0.183
progress: 13740.0 s, 51385.3 tps, lat 0.156 ms stddev 0.188
progress: 13800.0 s, 51640.2 tps, lat 0.155 ms stddev 0.177
progress: 13860.0 s, 51820.7 tps, lat 0.154 ms stddev 0.176
progress: 13920.0 s, 52041.9 tps, lat 0.154 ms stddev 0.179
progress: 13980.0 s, 52001.0 tps, lat 0.154 ms stddev 0.178
progress: 14040.0 s, 52189.3 tps, lat 0.153 ms stddev 0.176
progress: 14100.0 s, 51897.9 tps, lat 0.154 ms stddev 0.179
progress: 14160.0 s, 52066.4 tps, lat 0.154 ms stddev 0.180
progress: 14220.0 s, 52257.9 tps, lat 0.153 ms stddev 0.178
progress: 14280.0 s, 51850.1 tps, lat 0.154 ms stddev 0.210
......
.........
...........
Now in this third session we will monitor the database to see what’s going on. You can do something like below to check where we are going.
I have used below query to check where we are going, current XIDs, how close we are to our target of wraparound ..
Open another session to check log files, if they are reporting any hints, warnings or errors
After ~1 hour of test run, I have started seeing below warnings in the log files.
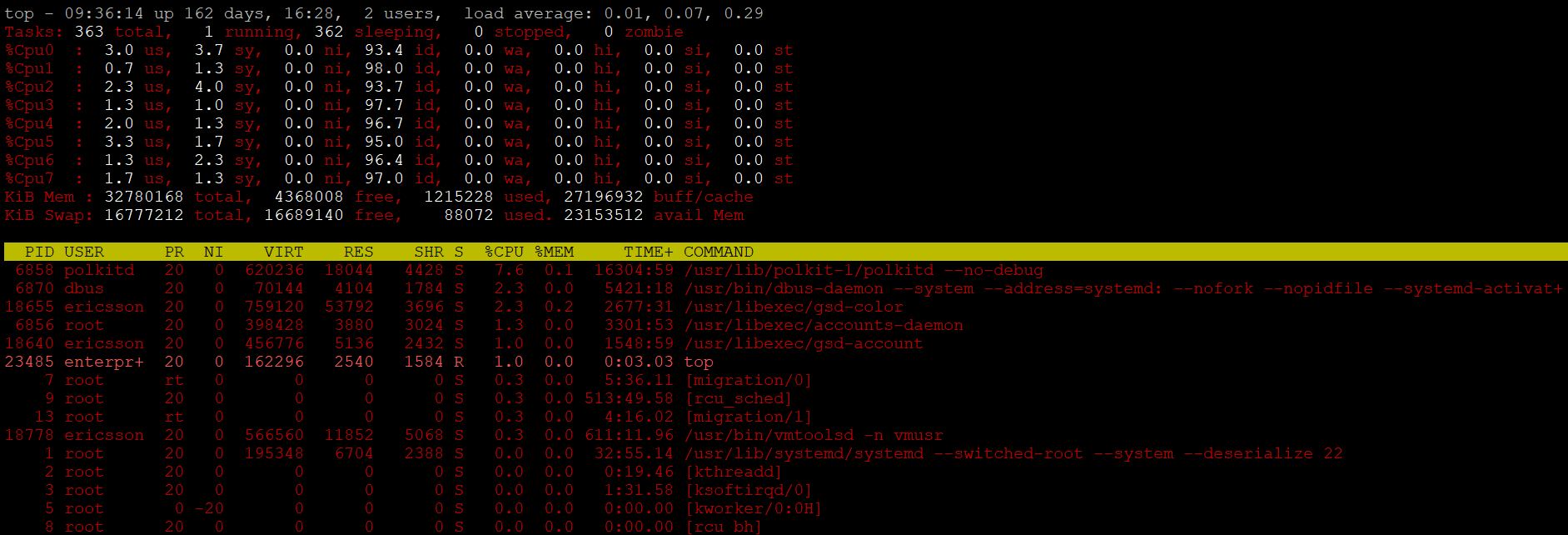
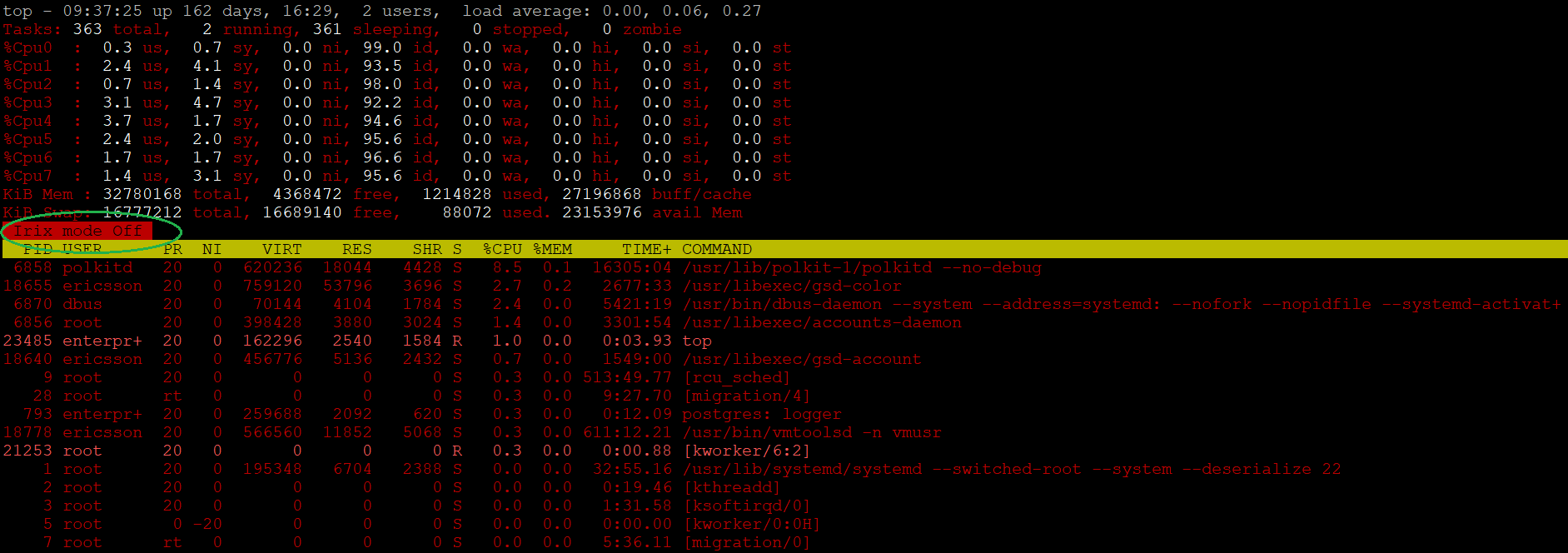
Now, let’s monitor system stats too to see overall load, processes their commands etc.
Lets check our screen 3 to see where we are in terms on oldest current XID and percent towards wraparound, and I see XID numbers are not increasing and we have reached 107% towards wraparound (strange, why it goes beyond 100%).
Let’s connect with the database and see what happens when we try to do both SELECT & UPDATE statements …
Alright, so with transaction wraparound is already there, we only be able to run SELECT queries, but DMLS will fail with a message printed to stop the database and vacuum it in single-user mode.
The easiest way to get the highest TXID age value back down is to force a vacuum on the entire database cluster. And the best way to do this cluster-wide vacuum is the vacuumdb binary utility that comes with PostgreSQL. I will cover it in my next post as this post is all about simulating wraparounds.