



• Program global area (PGA)
PGA is memory specific to operating process that is not shared by other processes in the system. Because PGA is process specific, it is never allocated in the SGA. Access to the PGA is exclusive to the server process.
An analogy for a PGA is a temporary countertop workspace used by a file clerk. In this analogy, the file clerk is the server process doing work on behalf of the customer (client process). The clerk clears a section of the countertop, uses the workspace to store details about the customer request and to sort the folders requested by the customer, and then gives up the space when the work is done.
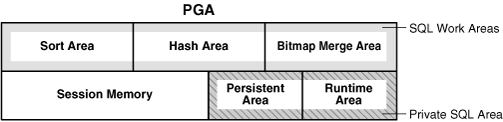
Not all of the PGA areas will exist in every case. PGA is subdivided into different areas.
– Session Memory: Also known as Stack Space (Session Memory).
– Private SQL Area:
This area holds information about a parsed SQL statement and other session specific information for processing for processing. When a server process executes SQL or PL/SQL code, the process uses the private SQL area to store bind variable values, query execution state information, and query execution work areas.
Private SQL Area is subdivided in to following parts:
Run-Time Area: This area contains query execution state information. For example, the run-time area tracks the number of rows retrieved so far in a full table scan.
Persistent Area: Area contains bind variable values.
– SQL Work Areas:
This area is a combination of Sort Area, Hash Area and Bitmap Merge Area. A sort operator uses the sort area to sort a set of rows. Similarly, a hash join operator uses a hash area to build a hash table from its left input, whereas a bitmap merge uses the bitmap merge area to merge data retrieved from scans of multiple bitmap indexes.
WORKAREA_SIZE_POLICY (AUTO | MANUAL) specifies the policy for sizing work areas. When set to Auto, Work areas used by memory-intensive operators (such as sort, group-by, hash-join, bitmap merge, & bitmap create) are sized automatically.
PGA_AGGREGATE_TARGET specifies the target aggregate PGA memory available to all server processes attached to the instance.
Setting PGA_AGGREGATE_TARGET to a nonzero value has the effect of automatically setting the WORKAREA_SIZE_POLICY parameter to AUTO. This means that SQL working areas used by memory-intensive SQL operators (such as sort, group-by, hash-join, bitmap merge, and bitmap create) will be automatically sized. A nonzero value for this parameter is the default since, unless you specify otherwise, Oracle sets it to 20% of the SGA or 10 MB, whichever is greater.
Setting PGA_AGGREGATE_TARGET to 0 automatically sets the WORKAREA_SIZE_POLICY parameter to MANUAL. This means that SQL workareas are sized using the *_AREA_SIZE parameters.
In below image, a pointer (Cursor) pointing towards ‘Private SQL Area’ to fetch information. The client process is responsible for managing private SQL areas.

* NOTE: For dedicated sessions, the UGA is a part of the RAM heap in the PGA that controls user sessions space for sorting and hash joins. If you are forced to use shared servers (the Multi-threaded Server or MTS) the UGA is inside the SGA large_pool_size region).
In sum, when using a dedicated connection, the User Global Area (UGA) supplements the PGA with additional memory for the user’s session, such as private SQL areas and other session-specific information such as sorting and session message queues.
………………………………………………………….
• UGA (User Global Area)
The UGA is session memory, which is memory allocated for session variables, such as logon information, and other information required by a database session. Essentially, the UGA stores the session state.

The UGA must be available to a database session for the life of the session. For this reason, the UGA cannot be stored in the PGA when using a shared server connection because the PGA is specific to a single process. Therefore, the UGA is stored in the SGA when using shared server connections, enabling any shared server process access to it. When using a dedicated server connection, the UGA is stored in the PGA.
UGA has following sections:
Session Variables –
OLAP Pool – This sessions opens automatically whenever a user queries a dimensional object like CUBE.



