There are numerous utilities, options, and methods available for migrating and moving data between Oracle databases, yet Oracle Data Pump remains one of the most widely used tools. A significant number of DBAs are very comfortable with Data Pump, as it has been a trusted utility for a long time (originally as exp and imp). Its stability, user-friendliness, and robust capabilities make it a top choice for handling large data migrations, backup, and restore operations.
However, one area where DBAs still often face challenges is troubleshooting when issues arise. When a Data Pump job fails, performs poorly, or behaves unexpectedly, it can be unclear where to start, what logs to review, or what checks to perform. Many find it difficult to pinpoint the source of the problem and make adjustments to optimize performance or resolve issues.
Today’s post focuses on troubleshooting Data Pump performance and functionality issues, sharing the steps I typically follow when diagnosing problems. We’ll cover key areas to investigate, like log file analysis, parameter tuning, network considerations, and common bottlenecks. These steps aim to provide a practical guide to understanding and resolving Data Pump issues and optimizing your data movement processes.
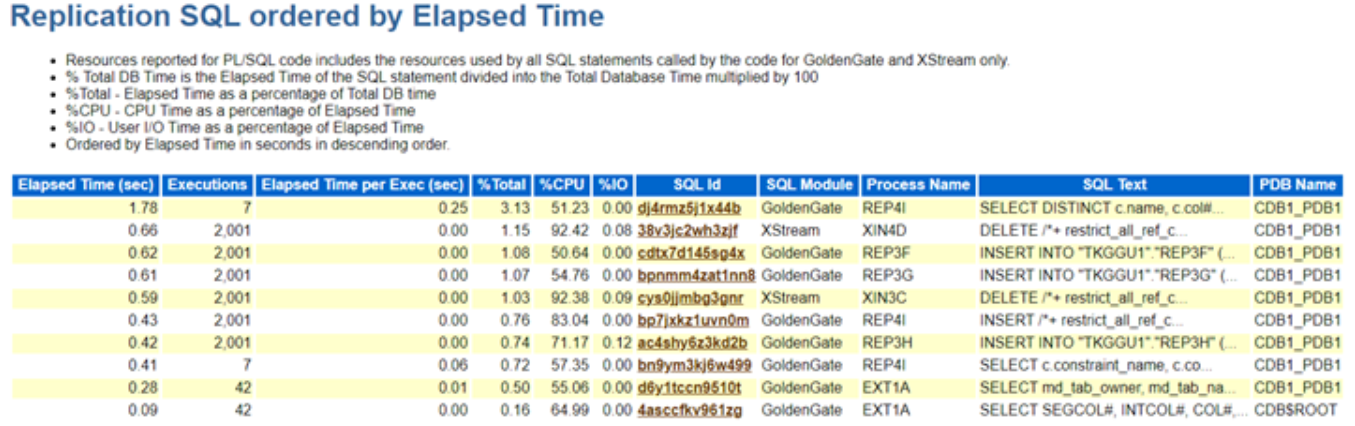
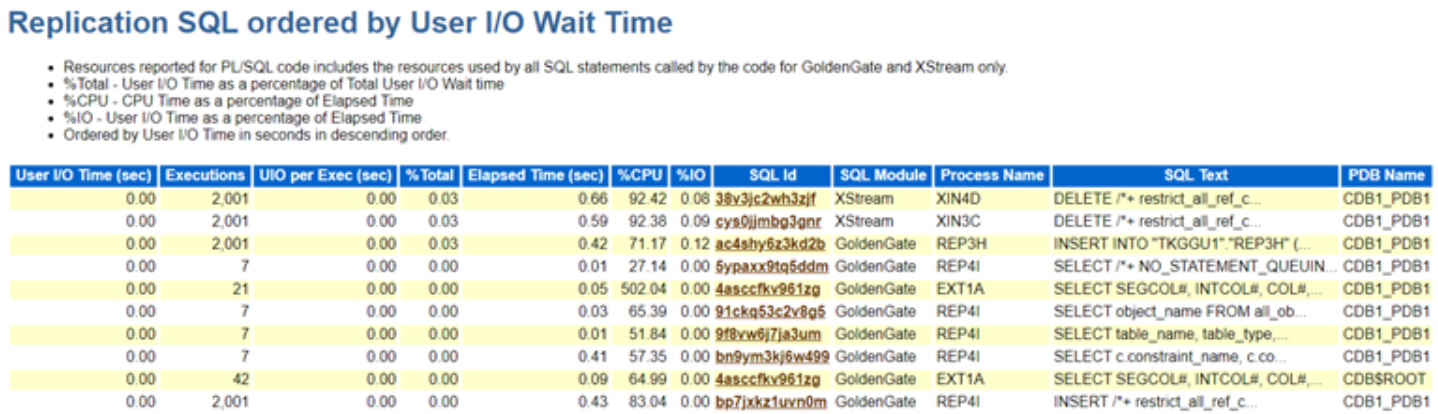
Option 1: Generate an AWR Report to Assess Database Performance
Start by generating an AWR (Automatic Workload Repository) report to gain insight into the database’s overall performance during the relevant period. Adjusting the AWR snapshot interval to 15 minutes is recommended for a more granular view. This approach reduces the chances of averaging out short performance spikes, allowing you to capture transient issues more effectively.
exec dbms_workload_repository.modify_snapshot_settings(null, 15);
exec dbms_workload_repository.create_snapshot;
Option 2: Enable SQL Trace for Data Pump Processes or Specific SQL IDs
Optionally, you can enable SQL trace for the Data Pump processes (dm for the master process and dw for worker processes) or for specific SQL statements by SQL ID. This will help isolate SQL-level performance issues affecting the Data Pump job.
alter system set events 'sql_trace {process: pname = dw | process: pname = dm} level=8';
alter system set events 'sql_trace[SQL: 8krc88r46raff]';
Option 3: Run Data Pump Job with Detailed Trace Enabled
For enhanced tracing, run the Data Pump job with additional trace options, which provide more comprehensive output. Including metrics=yes, logtime=all, and trace=1FF0300 in the command enables detailed logging of both timing and activity metrics. Tracing can be enabled by specifying an 7 digit hexadecimal mask in the TRACE parameter of Export DataPump (expdp) or Import DataPump (impdp). The first three digits enable tracing for a specific Data Pump component, while the last four digits are usually: 0300.
expdp ... metrics=yes logtime=all trace=1FF0300
impdp ... metrics=yes logtime=all trace=1FF0300
Data Pump tracing can also be started with a line with EVENT 39089 in the initialization parameter file. This method should only be used to trace the Data Pump calls in an early state, e.g. if details are needed about the DBMS_DATAPUMP.OPEN API call. Trace level 0x300 will trace all Data Pump client processes.
-- Enable event
ALTER SYSTEM SET EVENTS = '39089 trace name context forever, level 0x300' ;
-- Disable event
ALTER SYSTEM SET EVENTS = '39089 trace name context off' ;
Option 4: Review Data Pump Trace Files
Locate and analyze the Data Pump trace files stored in the Oracle trace directory. The master control process file names typically contain *dm*, while worker process files include *dw*. These files provide insights into the processes, job details, and potential error sources during execution.
Option 5: Activate SQL_TRACE on specific Data Pump process with higher trace level.
Lets assume we see that the Data Pump Master process (DM00) has SID: 143 and serial#: 50 and the Data Pump Worker process (DW01) has SID: 150 and serial#: 17. These details can be used to activate SQL tracing in SQL*Plus with DBMS_SYSTEM.SET_EV, e.g.:
-- In SQL*Plus, activate SQL tracing with DBMS_SYSTEM and SID/SERIAL#
-- Syntax: DBMS_SYSTEM.SET_EV([SID],[SERIAL#],[EVENT],[LEVEL],'')
-- Example to SQL_TRACE Worker process with level 4 (Bind values):
execute sys.dbms_system.set_ev(150,17,10046,4,'');
-- and stop tracing:
execute sys.dbms_system.set_ev(150,17,10046,0,'');
-- Example to SQL_TRACE Master Control process with level 8 (Waits):
execute sys.dbms_system.set_ev(143,50,10046,8,'');
-- and stop tracing:
execute sys.dbms_system.set_ev(143,50,10046,0,'');
Option 6: Use the Data Pump Log Analyzer
I’ve personally used the Data Pump Log Analyzer for some time and have found it to be incredibly user-friendly, making it simple to understand the performance and runtime statistics of Data Pump jobs. This tool is highly effective in streamlining troubleshooting efforts, quickly identifying bottlenecks, and delivering clear insights into job performance. It’s a fantastic addition to a DBA’s toolkit and provides valuable capabilities that aren’t typically found in standard scripts. The Data Pump Log Analyzer has been tested with Data Pump log files across various database versions, including those generated by Data Pump client (expdp/impdp), Zero Downtime Migration (ZDM), OCI Database Migration Service (DMS), and Data Pump API (DBMS_DATAPUMP).The Data Pump Log Analyzer is a Python-based command-line utility designed for in-depth analysis of Oracle Data Pump log files. It goes beyond basic log review by offering detailed, structured insights into key performance metrics, errors, and process details. This tool can be particularly useful for DBAs needing a quick and comprehensive view of Data Pump job behavior, helping with issue diagnosis and performance optimization. Link to read and download or a more detailed guide on it’s usage Link
With the Data Pump Log Analyzer, you get:
- Detailed Operations and Processing Metrics: Granular information on data operations for pinpoint analysis.
- Error and ORA- Code Analysis: Summaries and explanations of encountered errors for easier troubleshooting.
- Object-Type Breakdown and Processing Times: Insight into performance by object type, aiding in performance tuning.
- Data Pump Worker Performance: Analyzes individual worker processes for any lagging tasks.
- Summarized Schema, Table, Partition Details: Overview of data handled by each schema, table, or partition.
- Instance-Based Data Analysis (for Oracle 21c and later): Statistics by instance for performance evaluation in multitenant setups.
- Flexible Output Options: Filter, sort, and export analysis results to text or HTML for efficient sharing and record-keeping.
One below is with basic syntax to get operational details.
$ python3 dpla.py import.log
========================
Data Pump Log Analyzer
========================
...
Operation Details
~~~~~~~~~~~~~~~~~
Operation: Import
Data Pump Version: 19.23.0.0.0
DB Info: Oracle Database 19c EE Extreme Perf Release 19.0.0.0.0
Job Name: FATDBAJOB1
Status: COMPLETED
Processing: -
Errors: 1301
ORA- Messages: 1267
Start Time: 2024-08-21 01:30:45
End Time: 2024-08-21 11:43:11
Runtime: 35:03:06
Data Processing
~~~~~~~~~~~~~~~
Parallel Workers: 104
Schemas: 47
Objects: 224718
Data Objects: 188131
Overall Size: 19.11 TB
Use flag ‘-e’ to view all ORA- messages encountered during the Data Pump operation, or optionally you can filter our specific errors as well i.e. ‘-e ORA-39082 ORA-31684′.
python3 dpla.py import.log -e
========================
Data Pump Log Analyzer
========================
...
ORA- MESSAGES DETAILS
~~~~~~~~~~~~~~~~~~~~~
(sorted by count):
Message Count
--------------------------------------------------------------------------------------------------- ---------
ORA-39346: data loss in character set conversion for object COMMENT 919
ORA-39082: Object type PACKAGE BODY created with compilation warnings 136
ORA-39346: data loss in character set conversion for object PACKAGE_BODY 54
ORA-39082: Object type TRIGGER created with compilation warnings 36
ORA-39082: Object type PROCEDURE created with compilation warnings 29
ORA-31684: Object type USER already exists 27
ORA-39111: Dependent object type PASSWORD_HISTORY skipped, base object type USER already exists 27
ORA-39346: data loss in character set conversion for object PACKAGE 18
ORA-39082: Object type PACKAGE created with compilation warnings 10
ORA-39082: Object type VIEW created with compilation warnings 7
ORA-39346: data loss in character set conversion for object PROCEDURE 2
ORA-39082: Object type FUNCTION created with compilation warnings 2
--------------------------------------------------------------------------------------------------- ---------
Total 1267
--------------------------------------------------------------------------------------------------- ---------
Use flag ‘-o’ to see details about which types of database objects were involved in the Data Pump operation.
python3 dpla.py import.log -o
========================
Data Pump Log Analyzer
========================
...
Object Count Seconds Workers Duration
---------------------------------- ---------- ----------- ----------- ------------
SCHEMA_EXPORT/TABLE/TABLE_DATA 188296 6759219 128 6759219
CONSTRAINT 767 37253 1 37253
TABLE 2112 3225 51 156
COMMENT 26442 639 128 18
PACKAGE_BODY 197 125 128 5
OBJECT_GRANT 5279 25 1 25
TYPE 270 6 1 6
ALTER_PROCEDURE 149 5 2 3
ALTER_PACKAGE_SPEC 208 4 3 2
PACKAGE 208 3 3 1
PROCEDURE 149 2 2 1
...
---------------------------------- ---------- ----------- ----------- ------------
Total 224755 6800515 128 6796697
---------------------------------- ---------- ----------- ----------- ------------
Hope It Helped!
Prashant Dixit