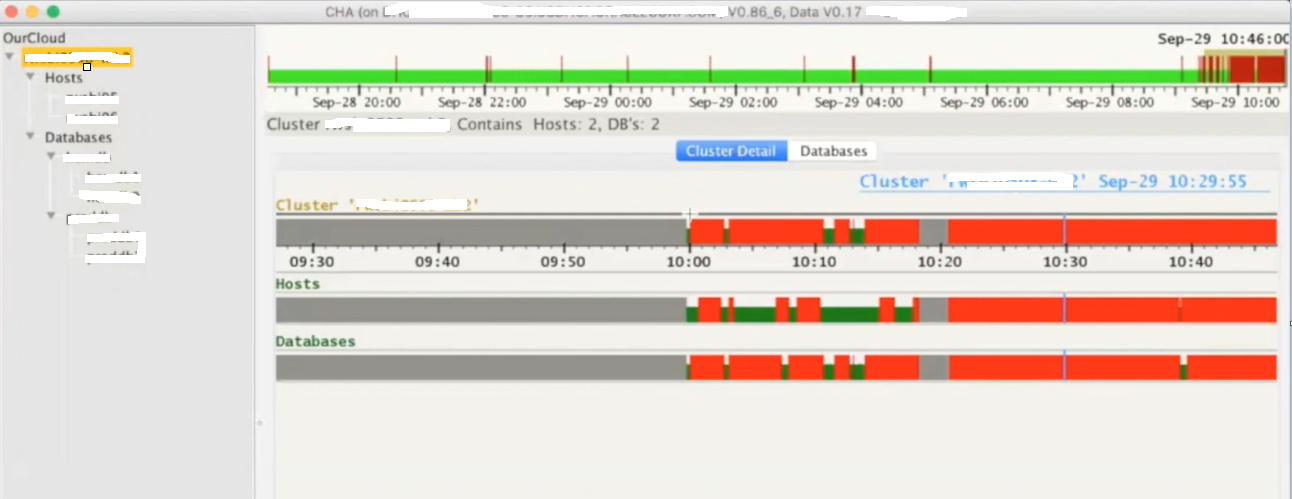
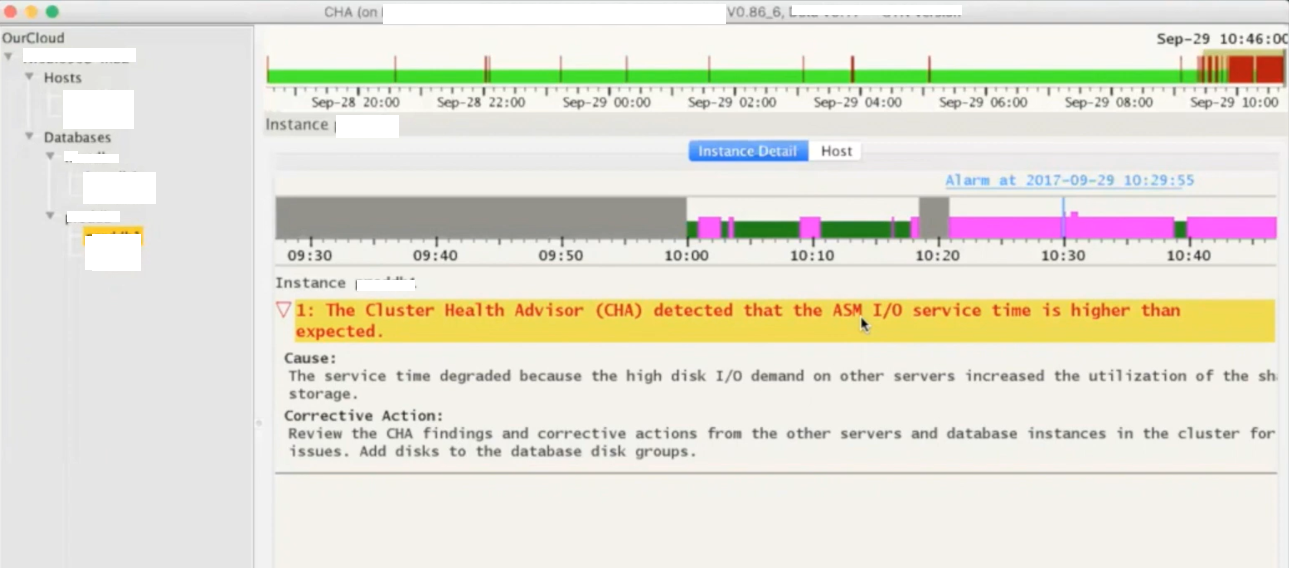
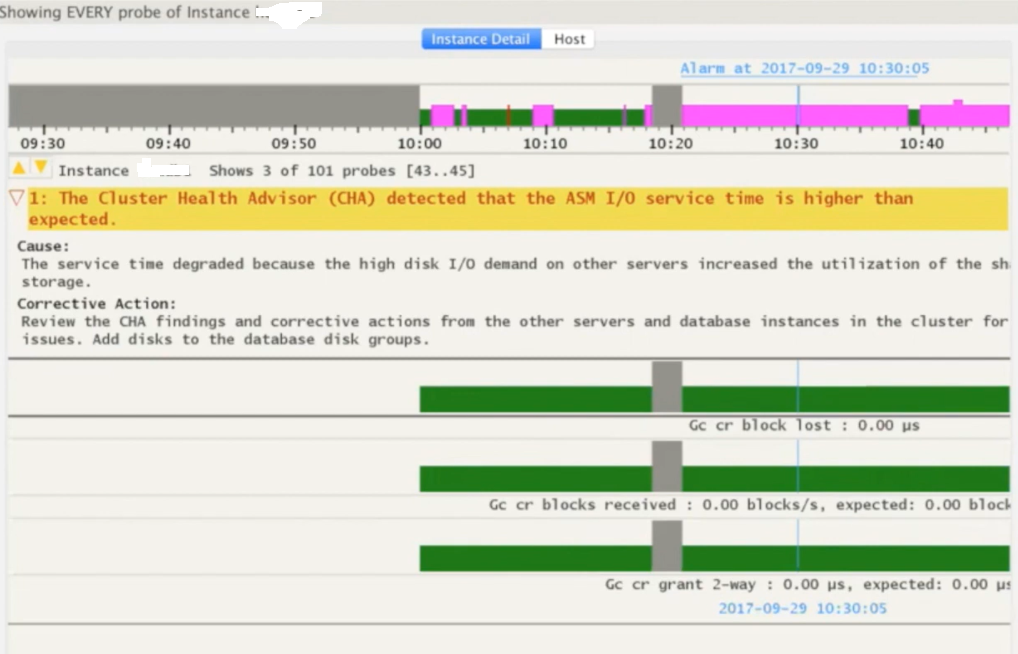
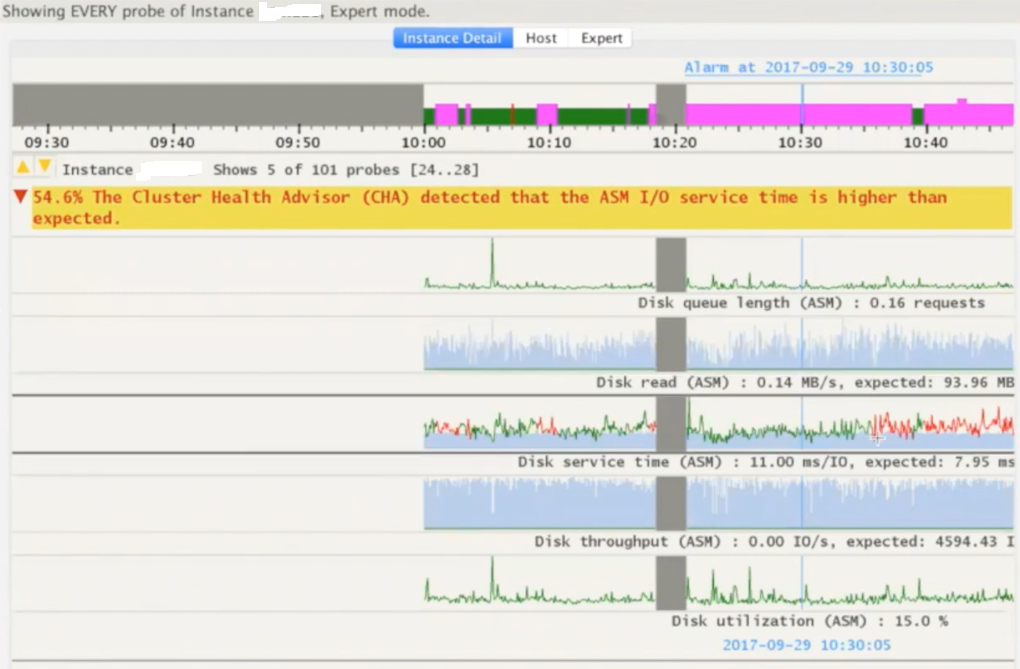
Below provided are steps to call and a sample health check report generated for a 2 node RAC system via ORAchk Tool.
link to download: https://support.oracle.com/epmos/faces/SearchDocDisplay?_adf.ctrl-state=kfoe5ynno_4&_afrLoop=178033262862018
Note ID: 1268927.2
=======================================================================
[oracle@dixitdb12v dixit]$ ./orachk
This version of orachk was released on 09-Oct-2014 and its older than 120 days. No new version of orachk is available in RAT_UPGRADE_LOC. It is highly recommended that you download the latest version of orachk from my oracle support to ensure the highest level of accuracy of the data contained within the report.
Do you want to continue running this version? [y/n][y]y
CRS stack is running and CRS_HOME is not set. Do you want to set CRS_HOME to /opt/app/grid/11.2.0/grid?[y/n][y]y
Checking ssh user equivalency settings on all nodes in cluster
Node dixitdb13v is configured for ssh user equivalency for oracle user
Searching for running databases . . . . .
. .
List of running databases registered in OCR
1. TESTRAC
2. None of above
Select databases from list for checking best practices. For multiple databases, select 1 for All or comma separated number like 1,2 etc [1-2][1].1
. .
Checking Status of Oracle Software Stack – Clusterware, ASM, RDBMS
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
——————————————————————————————————-
Oracle Stack Status
——————————————————————————————————-
Host Name CRS Installed RDBMS Installed CRS UP ASM UP RDBMS UP DB Instance Name
——————————————————————————————————-
dixitdb12v Yes Yes Yes Yes Yes TESTRAC1
dixitdb13v Yes Yes Yes Yes Yes TESTRAC2
——————————————————————————————————-
Copying plug-ins
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . .
18 of the included audit checks require root privileged data collection . If sudo is not configured or the root password is not available, audit checks which require root privileged data collection can be skipped.
1. Enter 1 if you will enter root password for each host when prompted
2. Enter 2 if you have sudo configured for oracle user to execute root_orachk.sh script
3. Enter 3 to skip the root privileged collections
4. Enter 4 to exit and work with the SA to configure sudo or to arrange for root access and run the tool later.
Please indicate your selection from one of the above options for root access[1-4][1]:- 1
*** Checking Best Practice Recommendations (PASS/WARNING/FAIL) ***
Collections and audit checks log file is
/home/oracle/dixit/orachk_dixitdb12v_TESTRAC_022715_032812/log/orachk.log
Running orachk in serial mode because expect(/usr/bin/expect) is not available to supply root passwords on remote nodes
NOTICE: Installing the expect utility (/usr/bin/expect) will allow orachk to gather root passwords at the beginning of the process and execute orachk on all nodes in parallel speeding up the entire process. For more info – http://www.nist.gov/el/msid/expect.cfm. Expect is available for all major platforms. See User Guide for more details.
Checking for prompts in /home/oracle/.bash_profile on dixitdb12v for oracle user…
Checking for prompts in /home/oracle/.bash_profile on dixitdb13v for oracle user…
=============================================================
Node name – dixitdb12v
=============================================================
Collecting – ASM Disk Groups
Collecting – ASM Disk I/O stats
Collecting – ASM Diskgroup Attributes
Collecting – ASM disk partnership imbalance
Collecting – ASM diskgroup attributes
Collecting – ASM diskgroup usable free space
Collecting – ASM initialization parameters
Collecting – Active sessions load balance for TESTRAC database
Collecting – Archived Destination Status for TESTRAC database
Collecting – Cluster Interconnect Config for TESTRAC database
Collecting – Database Archive Destinations for TESTRAC database
Collecting – Database Files for TESTRAC database
Collecting – Database Instance Settings for TESTRAC database
Collecting – Database Parameters for TESTRAC database
Collecting – Database Parameters for TESTRAC database
Collecting – Database Properties for TESTRAC database
Collecting – Database Registry for TESTRAC database
Collecting – Database Sequences for TESTRAC database
Collecting – Database Undocumented Parameters for TESTRAC database
Collecting – Database Undocumented Parameters for TESTRAC database
Collecting – Database Workload Services for TESTRAC database
Collecting – Dataguard Status for TESTRAC database
Collecting – Files not opened by ASM
Collecting – Log Sequence Numbers for TESTRAC database
Collecting – Percentage of asm disk Imbalance
Collecting – Process for shipping Redo to standby for TESTRAC database
Collecting – RDBMS Feature Usage for TESTRAC database
Collecting – Redo Log information for TESTRAC database
Collecting – Standby redo log creation status before switchover for TESTRAC database
Collecting – /proc/cmdline
Collecting – /proc/modules
Collecting – CPU Information
Collecting – CRS active version
Collecting – CRS oifcfg
Collecting – CRS software version
Collecting – CSS Reboot time
Collecting – CSS disktimout
Collecting – Cluster interconnect (clusterware)
Collecting – Clusterware OCR healthcheck
Collecting – Clusterware Resource Status
Collecting – DiskFree Information
Collecting – DiskMount Information
Collecting – Huge pages configuration
Collecting – Interconnect network card speed
Collecting – Kernel parameters
Collecting – Maximum number of semaphore sets on system
Collecting – Maximum number of semaphores on system
Collecting – Maximum number of semaphores per semaphore set
Collecting – Memory Information
Collecting – NUMA Configuration
Collecting – Network Interface Configuration
Collecting – Network Performance
Collecting – Network Service Switch
Collecting – OS Packages
Collecting – OS version
Collecting – Operating system release information and kernel version
Collecting – Oracle Executable Attributes
Collecting – Patches for Grid Infrastructure
Collecting – Patches for RDBMS Home
Collecting – Shared memory segments
Collecting – Table of file system defaults
Collecting – Voting disks (clusterware)
Collecting – number of semaphore operations per semop system call
Preparing to run root privileged commands dixitdb12v. Please enter root password when prompted.
root@dixitdb12v’s password:
Collecting – ACFS Volumes status
Collecting – Broadcast Requirements for Networks
Collecting – CRS user time zone check
Collecting – Custom rc init scripts (rc.local)
Collecting – Disk Information
Collecting – Grid Infastructure user shell limits configuration
Collecting – Interconnect interface config
Collecting – Network interface stats
Collecting – Number of RDBMS LMS running in real time
Collecting – OLR Integrity
Collecting – Root user limits
Collecting – Verify no database server kernel out of memory errors
Collecting – root time zone check
Collecting – slabinfo
Data collections completed. Checking best practices on dixitdb12v.
————————————————————————————–
WARNING => Cluster Health Monitor (CHM) repository does not provide recommended level of retention
INFO => Important Automatic Storage Management (ASM) Notes and Technical White Papers
FAIL => Bash is vulnerable to code injection (CVE-2014-6271)
WARNING => ARCHIVELOG mode is disabled for TESTRAC
INFO => $CRS_HOME/log/hostname/client directory has too many older log files.
INFO => ORA-00600 errors found in alert log for TESTRAC
INFO => At some times checkpoints are not being completed for TESTRAC
INFO => Some data or temp files are not autoextensible for TESTRAC
INFO => oracleasm (asmlib) module is NOT loaded
WARNING => Shell limit soft nproc for DB is NOT configured according to recommendation
WARNING => kernel.shmmax parameter is NOT configured according to recommendation
WARNING => Database Parameter memory_target is not set to the recommended value on TESTRAC1 instance
FAIL => Operating system hugepages count does not satisfy total SGA requirements
WARNING => NIC bonding is not configured for interconnect
WARNING => NIC bonding is NOT configured for public network (VIP)
WARNING => OSWatcher is not running as is recommended.
INFO => Jumbo frames (MTU >= 8192) are not configured for interconnect
WARNING => NTP is not running with correct setting
WARNING => Database parameter DB_BLOCK_CHECKING on PRIMARY is NOT set to the recommended value. for TESTRAC
FAIL => Flashback on PRIMARY is not configured for TESTRAC
INFO => Operational Best Practices
INFO => Database Consolidation Best Practices
INFO => Computer failure prevention best practices
INFO => Data corruption prevention best practices
INFO => Logical corruption prevention best practices
INFO => Database/Cluster/Site failure prevention best practices
INFO => Client failover operational best practices
WARNING => fast_start_mttr_target should be greater than or equal to 300. on TESTRAC1 instance
INFO => Information about hanganalyze and systemstate dump
WARNING => Package unixODBC-2.2.14-11.el6-i686 is recommended but NOT installed
WARNING => Package unixODBC-devel-2.2.14-11.el6-i686 is recommended but NOT installed
FAIL => Table AUD$[FGA_LOG$] should use Automatic Segment Space Management for TESTRAC
INFO => Database failure prevention best practices
WARNING => Database Archivelog Mode should be set to ARCHIVELOG for TESTRAC
FAIL => Primary database is NOT protected with Data Guard (standby database) for real-time data protection and availability for TESTRAC
INFO => Parallel Execution Health-Checks and Diagnostics Reports for TESTRAC
WARNING => Package unixODBC-devel-2.2.14-11.el6-x86_64 is recommended but NOT installed
WARNING => Linux transparent huge pages are enabled
WARNING => vm.min_free_kbytes should be set as recommended.
INFO => Oracle recovery manager(rman) best practices
WARNING => RMAN controlfile autobackup should be set to ON for TESTRAC
INFO => Consider increasing the COREDUMPSIZE size
INFO => Consider investigating changes to the schema objects such as DDLs or new object creation for TESTRAC
INFO => Consider investigating the frequency of SGA resize operations and take corrective action for TESTRAC
Best Practice checking completed.Checking recommended patches on dixitdb12v.
———————————————————————————
Collecting patch inventory on CRS HOME /opt/app/grid/11.2.0/grid
Collecting patch inventory on ORACLE_HOME /opt/app/oracle/product/11.2.0/dbhome_1
———————————————————————————
1 Recommended CRS patches for 112040 from /opt/app/grid/11.2.0/grid on dixitdb12v
———————————————————————————
Patch# CRS ASM RDBMS RDBMS_HOME Patch-Description
———————————————————————————
19769489 no yes /opt/app/oracle/product/11.2.0/dbhome_1Patch description: “Database Patch Set Update : 11.2.0.4.5 (19769489)”
———————————————————————————
———————————————————————————
1 Recommended RDBMS patches for 112040 from /opt/app/oracle/product/11.2.0/dbhome_1 on dixitdb12v
———————————————————————————
Patch# RDBMS ASM type Patch-Description
———————————————————————————
19769489 yes merge Patch description: “Database Patch Set Update : 11.2.0.4.5 (19769489)”
———————————————————————————
———————————————————————————
———————————————————————————
Clusterware patches summary report
———————————————————————————
Total patches Applied on CRS Applied on RDBMS Applied on ASM
———————————————————————————
1 0 1 0
———————————————————————————
———————————————————————————
RDBMS homes patches summary report
———————————————————————————
Total patches Applied on RDBMS Applied on ASM ORACLE_HOME
———————————————————————————
1 1 0 /opt/app/oracle/product/11.2.0/dbhome_1
———————————————————————————
=============================================================
Node name – dixitdb13v
=============================================================
Collecting – /proc/cmdline
Collecting – /proc/modules
Collecting – CPU Information
Collecting – CRS active version
Collecting – CRS oifcfg
Collecting – CRS software version
Collecting – Cluster interconnect (clusterware)
Collecting – DiskFree Information
Collecting – DiskMount Information
Collecting – Huge pages configuration
Collecting – Interconnect network card speed
Collecting – Kernel parameters
Collecting – Maximum number of semaphore sets on system
Collecting – Maximum number of semaphores on system
Collecting – Maximum number of semaphores per semaphore set
Collecting – Memory Information
Collecting – NUMA Configuration
Collecting – Network Interface Configuration
Collecting – Network Performance
Collecting – Network Service Switch
Collecting – OS Packages
Collecting – OS version
Collecting – Operating system release information and kernel version
Collecting – Oracle Executable Attributes
Collecting – Patches for Grid Infrastructure
Collecting – Patches for RDBMS Home
Collecting – Shared memory segments
Collecting – Table of file system defaults
Collecting – number of semaphore operations per semop system call
Preparing to run root privileged commands dixitdb13v. Please enter root password when prompted.
root@dixitdb13v’s password:
Data collections completed. Checking best practices on dixitdb13v.
————————————————————————————–
FAIL => Bash is vulnerable to code injection (CVE-2014-6271)
INFO => $CRS_HOME/log/hostname/client directory has too many older log files.
INFO => ORA-00600 errors found in alert log for TESTRAC
INFO => At some times checkpoints are not being completed for TESTRAC
INFO => oracleasm (asmlib) module is NOT loaded
WARNING => Shell limit soft nproc for DB is NOT configured according to recommendation
WARNING => kernel.shmmax parameter is NOT configured according to recommendation
WARNING => Database Parameter memory_target is not set to the recommended value on TESTRAC2 instance
FAIL => Operating system hugepages count does not satisfy total SGA requirements
WARNING => NIC bonding is not configured for interconnect
WARNING => NIC bonding is NOT configured for public network (VIP)
WARNING => OSWatcher is not running as is recommended.
INFO => Jumbo frames (MTU >= 8192) are not configured for interconnect
WARNING => NTP is not running with correct setting
WARNING => Database parameter DB_BLOCK_CHECKING on PRIMARY is NOT set to the recommended value. for TESTRAC
WARNING => fast_start_mttr_target should be greater than or equal to 300. on TESTRAC2 instance
INFO => IMPORTANT: Oracle Database Patch 17478514 PSU is NOT applied to RDBMS Home /opt/app/oracle/product/11.2.0/dbhome_1
WARNING => Package unixODBC-2.2.14-11.el6-i686 is recommended but NOT installed
WARNING => Package unixODBC-devel-2.2.14-11.el6-i686 is recommended but NOT installed
WARNING => Package unixODBC-devel-2.2.14-11.el6-x86_64 is recommended but NOT installed
WARNING => Linux transparent huge pages are enabled
WARNING => vm.min_free_kbytes should be set as recommended.
INFO => Consider increasing the COREDUMPSIZE size
Best Practice checking completed.Checking recommended patches on dixitdb13v.
———————————————————————————
Collecting patch inventory on CRS HOME /opt/app/grid/11.2.0/grid
Collecting patch inventory on ORACLE_HOME /opt/app/oracle/product/11.2.0/dbhome_1
———————————————————————————
1 Recommended CRS patches for 112040 from /opt/app/grid/11.2.0/grid on dixitdb13v
———————————————————————————
Patch# CRS ASM RDBMS RDBMS_HOME Patch-Description
———————————————————————————
18706472 no no /opt/app/oracle/product/11.2.0/dbhome_1GRID INFRASTRUCTURE SYSTEM PATCH 11.2.0.4.3
———————————————————————————
———————————————————————————
1 Recommended RDBMS patches for 112040 from /opt/app/oracle/product/11.2.0/dbhome_1 on dixitdb13v
———————————————————————————
Patch# RDBMS ASM type Patch-Description
———————————————————————————
18706472 no merge GRID INFRASTRUCTURE SYSTEM PATCH 11.2.0.4.3
———————————————————————————
———————————————————————————
———————————————————————————
Clusterware patches summary report
———————————————————————————
Total patches Applied on CRS Applied on RDBMS Applied on ASM
———————————————————————————
1 0 0 0
———————————————————————————
———————————————————————————
RDBMS homes patches summary report
———————————————————————————
Total patches Applied on RDBMS Applied on ASM ORACLE_HOME
———————————————————————————
1 0 0 /opt/app/oracle/product/11.2.0/dbhome_1
———————————————————————————
———————————————————————————
CLUSTERWIDE CHECKS
———————————————————————————
———————————————————————————
Detailed report (html) – /home/oracle/dixit/orachk_dixitdb12v_TESTRAC_022715_032812/orachk_dixitdb12v_TESTRAC_022715_032812.html
UPLOAD(if required) – /home/oracle/dixit/orachk_dixitdb12v_TESTRAC_022715_032812.zip
Thanks
Prashant Dixit