Hi All,
Occasionally, anticipating the occurrence of a problem becomes unpredictable, and simultaneously, dealing manually with a transient issue to extract necessary information may not always be feasible (mainly due to the rapid resolution of the problem before we can initiate the extraction process). Additionally, there is a requirement for adaptability in the content we aim to extract.
The ensuing approach allows us to attain our primary objectives without resorting to invasive measures. There could be multiple use cases, few of the scenarios would be :
Case 1 : With little changes to it, you can make it employable for gathering solely the system state upon encountering a specific wait event.
Case 2: Can be utilized for gathering 10046, error stack, etc., for the obstructing session when a designated wait event is triggered concurrently with the execution of a known SQL statement (SQL_ID).
Case 3: Utilizable for obtaining hang analysis, system state, and additionally, 10046, error stack for the session causing the obstruction when a specific wait event is encountered.
Let me explain how we can utilize this quick, short but handy code to generate the diagnostic dump like hanganalyze / systemstate / errorstack / 10046 trace etc if any session is found to be waiting on any specific wait event for any specific period of time.
This is the simple script to collect diagnostic information with few of the customizable parameters or inputs i.e. ‘waitevent’ which is for the event we know we have the problem with, ‘seconds’ is the amount of time we think a session can wait on that session before we decide it is stuck and want to trigger dumping and ‘tid’ which is the session we are going to attach to run oradebug against. This could be the waiting session, a blocking session.
In the example, I have modified the code to collect diag info if any session is found to be waiting on “enq: TX – row lock contention” waits above 10 seconds.
set serverout on
spool logit.sql
declare
waitevent varchar2(100):='enq: TX - row lock contention';
seconds number :=10;
w1 v$session%rowtype;
w2 v$session%rowtype;
tid number := 0;
begin
loop
dbms_lock.sleep(seconds);
begin
select * into w1
from v$session
where event=waitevent and wait_time=0 and rownum=1;
dbms_lock.sleep(seconds);
select * into w2
from v$session
where wait_time=0
and sid=w1.sid
and event=waitevent
and seq#=w1.seq# ;
select spid into tid from v$process
where addr=(select paddr from v$session where sid=w2.blocking_session);
dbms_output.put_line('oradebug setospid '||tid);
dbms_output.put_line('oradebug unlimit');
dbms_output.put_line('oradebug hanganalyze 3'); /**If RAC then use -G all**/
dbms_output.put_line('oradebug tracefile_name');
dbms_output.put_line('exit');
exit;
exception
when no_data_found then null;
end;
end loop;
end;
/
exit
-- Result :
SQL>
oradebug setospid 6794
oradebug unlimit
oradebug hanganalyze 3
oradebug tracefile_name
exit
PL/SQL procedure successfully completed.
SQL>
The subsequent instance is intricate yet showcases versatility of this simple script. In this scenario, I encounter an intermittent issue involving sessions experiencing wait times due to TX enqueue row lock contention. While I may not be overly concerned about these sessions, it is crucial for me to understand the actions of the session causing the blockage. Given that I am aware of the SQL being executed during that period, I can leverage this information to ensure accurate trapping of the relevant event.
Here is something that you can do to alter it accordingly.
Let me create a row locking situation and see how it captures stats for a particular SQLID. Below is the row locking case that I have created to test how the scripts catches details for this SQLID ‘0jy18x4pff06k’
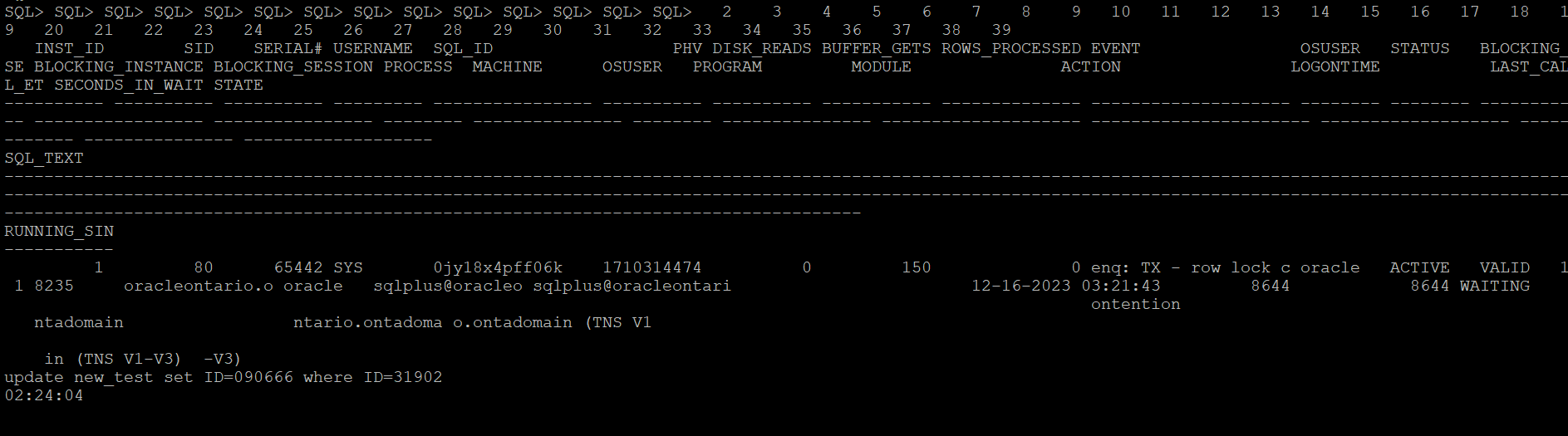
This is the modified version of the script which catches details for the SQL waiting on any specific wait event.
set serverout on
spool logit.sql
declare
waitevent varchar2(100):='enq: TX - row lock contention';
seconds number :=10;
w1 v$session%rowtype;
w2 v$session%rowtype;
tid number := 0;
begin
loop
dbms_lock.sleep(seconds);
begin
select * into w1
from v$session
where event=waitevent and wait_time=0 and sql_id='0jy18x4pff06k' and rownum=1;
dbms_lock.sleep(seconds);
select * into w2
from v$session
where wait_time=0
and sid=w1.sid
and event=waitevent
and seq#=w1.seq# ;
select spid into tid from v$process
where addr=(select paddr from v$session where sid=w2.blocking_session);
dbms_output.put_line('oradebug setospid '||tid);
dbms_output.put_line('oradebug unlimit');
dbms_output.put_line('oradebug dump errorstack 3');
dbms_output.put_line('oradebug dump errorstack 3');
dbms_output.put_line('oradebug dump errorstack 3');
dbms_output.put_line('oradebug event 10046 trace name context forever, level 8');
dbms_output.put_line('oradebug event 10200 trace name context forever, level 1');
dbms_output.put_line('oradebug event 10224 trace name context forever, level 1');
dbms_output.put_line('execute dbms_lock.sleep(20);');
dbms_output.put_line('oradebug event 10046 trace name context off');
dbms_output.put_line('oradebug event 10200 trace name context off');
dbms_output.put_line('oradebug event 10224 trace name context off');
dbms_output.put_line('exit');
exit;
exception
when no_data_found then null;
end;
end loop;
end;
/
exit
-- Result :
SQL>
oradebug setospid 6794
oradebug unlimit
oradebug dump errorstack 3
oradebug dump errorstack 3
oradebug dump errorstack 3
oradebug event 10046 trace name context forever, level 8
oradebug event 10200 trace name context forever, level 1
oradebug event 10224 trace name context forever, level 1
execute dbms_lock.sleep(20);
oradebug event 10046 trace name context off
oradebug event 10200 trace name context off
oradebug event 10224 trace name context off
exit
PL/SQL procedure successfully completed.
SQL>
The next what we can do to trap any such wait events of interest when it exceeds the behnchmark, you can put eveything in a shell script and run it in the loop and execute the oradebug code. Once finished you can look it in the diagnostic_dest for the dump file. For 11g and above, look under subdirectory trace under home directory of ADR.
Next once you have put it in the shell script format, you can call it in the nohup mode and the script will run in background and sit in a loop for the defined condition to hit.
[oracle@oracleontario ~]$ more exec
#!/bin/bash
sqlplus -s '/ as sysdba' @waitdumpv1
[oracle@oracleontario ~]$
[oracle@oracleontario ~]$ chmod 777 exec
[oracle@oracleontario ~]$
[oracle@oracleontario ~]$
[oracle@oracleontario ~]$ nohup ./exec > waitdump2.log
nohup: ignoring input and redirecting stderr to stdout
[oracle@oracleontario ~]$
[oracle@oracleontario ~]$ more waitdump1.log
[oracle@oracleontario ~]$ nohup ./exec > waitdump2.log
nohup: ignoring input and redirecting stderr to stdout
[oracle@oracleontario ~]$ more waitdump2.log
oradebug setospid 6794
oradebug unlimit
oradebug hanganalyze 3
oradebug tracefile_name
exit
PL/SQL procedure successfully completed.
[oracle@oracleontario ~]$
[oracle@oracleontario ~]$
Hope It Helped!
Prashant Dixit